| Issue |
Wuhan Univ. J. Nat. Sci.
Volume 30, Number 1, February 2025
|
|
|---|---|---|
| Page(s) | 21 - 31 | |
| DOI | https://doi.org/10.1051/wujns/2025301021 | |
| Published online | 12 March 2025 | |
Computer Science
CLC number: TP311
The Joint Model of Multi-Intent Detection and Slot Filling Based on Bidirectional Interaction Structure
基于双向交互结构的多意图识别与槽位填充联合模型
1 School of Digital Industry, Jiangxi Normal University, Shangrao 334000, Jiangxi, China
2 School of Computer Information Engineering, Jiangxi Normal University, Nanchang 330022, Jiangxi, China
3 Jiangxi Provincial Key Laboratory for High Performance Computing, Jiangxi Normal University, Nanchang 330022, Jiangxi, China
4 State International Science and Technology Cooperation Base of Networked Supporting Software, Jiangxi Normal University, Nanchang 330022, Jiangxi, China
† Corresponding author. E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
28
July
2024
Abstract
Intent detection and slot filling are two important components of natural language understanding. Because their relevance, joint training is often performed to improve performance. Existing studies mostly use a joint model of multi-intent detection and slot-filling with unidirectional interaction, which improves the overall performance of the model by fusing the intent information in the slot-filling part. On this basis, in order to further improve the overall performance of the model by exploiting the correlation between the two, this paper proposes a joint multi-intent detection and slot-filling model based on a bidirectional interaction structure, which fuses the intent encoding information in the encoding part of slot filling and fuses the slot decoding information in the decoding part of intent detection. Experimental results on two public multi-intent joint training datasets, MixATIS and MixSNIPS, show that the bidirectional interaction structure proposed in this paper can effectively improve the performance of the joint model. In addition, in order to verify the generalization of the bidirectional interaction structure between intent and slot, a joint model for single-intent scenarios is proposed on the basis of the model in this paper. This model also achieves excellent performance on two public single-intent joint training datasets, CAIS and SNIPS.
摘要
意图识别与槽位填充是自然语言理解的两个重要组成部分,由于两者的相关性, 所以常进行联合训练提高性能。现有研究多是采用单向交互的多意图识别与槽位填充联合模型,通过在槽位填充部分融合意图信息提高了模型整体性能。为了进一步利用两者的相关性提高模型整体性能,本文提出了基于双向交互结构的多意图识别与槽位填充联合模型,在槽位填充编码部分融合了意图编码信息,在意图识别解码部分融合了槽位解码信息。在MixATIS和MixSNIPS两个公共多意图联合训练数据集上的实验结果表明,该双向交互结构能有效提高联合模型的性能。此外,为了验证意图与槽位双向交互结构的泛化性,在本文模型的基础上提出了针对单意图场景的联合模型,在CAIS和SNIPS两个公共单意图联合训练数据集上也取得了优异的性能。
Key words: natural language understanding / multi-intent detection / slot filling / bidirectional interaction / joint training
关键字 : 自然语言理解 / 多意图识别 / 槽位填充 / 双向交互结构 / 联合训练
Cite this article: WANG Changjing, ZENG Xianghui, WANG Yuxin, et al. The Joint Model of Multi-Intent Detection and Slot Filling Based on Bidirectional Interaction Structure[J]. Wuhan Univ J of Nat Sci, 2025, 30(1): 21-31.
Biography: WANG Changjing, male, Ph.D., Professor, research direction: software formal method, trustworthy software. E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Foundation item: Supported by the National Nature Science Foundation of China(62462037, 62462036),Project for Academic and Technical Leader in Major Disciplines in Jiangxi Province (20232BCJ22013), Jiangxi Provincial Natural Science Foundation (20242BAB26017, 20232BAB202010), and Jiangxi Province Graduate Innovation Fund Project (YC2023-S320)
© Wuhan University 2025
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
0 Introduction
Natural Language Understanding (NLU) technology plays a vital role in task-based dialogue systems. NLU includes two main tasks: intent detection and slot filling[1], which allow the dialogue system to create a semantic framework to extract the specific needs of the user[2].
Intent detection can be regarded as a text classification task or multi-label classification task, and slot filling can be viewed as a sequence labeling task. As shown in Fig. 1, for the user statement: "Please Play Zhou Huajian's Friends", the system needs to identify the intent contained in the sentence: "Play Music", and find the slot values corresponding to this intent in the sentences: "Zhou Huajian's" and "Friends" (The slot labeling method used in Fig. 1 is the BIO method[3]).
 |
Fig. 1 Example of intent detection and slot filling |
Early research often trained two tasks separately[4-7]. However, due to their high correlation, recent work usually jointly models them to improve overall performance[8-13]. Previous work was mainly based on joint models of single-intent scenarios. However, in actual application scenarios, user statements may contain multiple intents, and the joint model of single-intent detection and slot filling (single-intent joint model) is challenging to meet the actual needs in some application scenarios. In recent years, some research has been dedicated to the joint model of multi-intent detection and slot filling (multi-intent joint model) that has a more extensive application scope. Qin et al[14] disclosed two datasets for joint training of multi-intent models and offered fine-grained intent information integration for the slot-filling task in the multi-intent joint model. Qin et al[15] utilized a non-autoregressive method to boost the accuracy and detection speed of intents and slots and merged intent encoding information into the slot-filling segment. Chen et al16] suggested a self-distillation multi-intent joint model. Cai[17] presented a multi-intent joint model that conducts explicit slot and intent mapping utilizing BERT (Bidirectional Encoder Representation from Transformers)[18]. All of the above multi-intent joint models use threshold determination for multi-intent judgment, which presents issues such as difficulty in determining the appropriate threshold and insufficient generalization of the model. In relation to the issues present in threshold determination, Chen et al[19] proposed a Threshold-Free Multi-intent NLU model (TFMN) based on Transformer[20], which transforms the multi-intent threshold determination problem into an intent number classification problem and fuses intent encoding information for the slot filling part. Most of the above multi-intent joint models adopt a unidirectional interaction structure from intent to slot, improving the overall performance of the model by guiding slot filling with intent information but lacking slot information guidance in the intent detection part.
On this basis, in order to further utilize the correlation between the two in the intent detection part, this paper proposes a joint model of multi-intent detection and slot filling based on a bidirectional interaction structure (MSBI). It fuses the intent encoding information in the encoding part of slot filling, and the slot decoding information in the decoding part of intent detection, thus achieving bidirectional interaction between intent and slot information. Compared with existing unidirectional interaction models, this approach significantly improves the performance of both multi-intent detection and slot-filling tasks, while also demonstrating strong generalization capability.
1 Related Work
Based on the number of intents that can be detected in a sentence, the joint model of intent detection and slot filling can be divided into two categories: the joint model of single-intent detection and slot filling (single-intent joint model) and the joint model of multi-intent detection and slot filling (multi-intent joint model). In the single-intent joint model, intent detection can be regarded as a text classification task. In the multi-intent joint model, intent detection can be viewed as a multi-label classification task.
Single-intent joint model: Goo et al [8] proposed a slot gate mechanism for learning the relationship between intent and slot, using the intent context vector to model the relationship from slot to intent to improve the performance of slot filling. Qin et al[9] transformed intent detection from a text classification task into a sequence labeling task, performing character-level intent detection and simultaneously integrating character-level intent information into the slot-filling part. Wang et al[10] proposed a bidirectional interaction model between intent and slot based on a gating mechanism, using the gating mechanism to extract relevant information between intent encoding and slot encoding and conducting bidirectional interaction through shared parameters. Liu et al[11] proposed a cooperative memory network for shared encoding of intent and slot and also annotated a Chinese joint training dataset CAIS. Teng et al[12] proposed a Chinese intent detection and slot-filling joint model, providing word information to the model through a multi-level character adapter and integrating intent decoding information into the slot-filling part. Hou et al[13] proposed a joint model based on prior knowledge and fused intent information into the information interaction layer for the slot-filling part.
The studies above all focus on single-intent scenarios. However, in some application scenarios, user sentences may contain multiple intents. Using a single-intent joint model can only identify one intent, potentially resulting in the loss of information about other intents.
Multi-intent joint model: Qin et al[14] introduced an intent-slot graph interaction layer to establish a strong correlation between slots and intents. This interaction layer is adaptively applied to each character, can automatically extract relevant intent information, and provides fine-grained intent information integration for slot filling. Qin et al[15] proposed a non-autoregressive multi-intent joint model and, at the same time, introduced a global and local slot-aware graph interaction layer to model the dependencies between slots and integrate intent information for slot filling. Chen et al[16] described multi-intent detection as a weakly supervised problem. They used a multi-instance learning method by designing a self-distillation auxiliary loop to enable interaction between intent and slot. Cai et al[17] proposed a BERT[18]-based multi-intent joint model and introduced a slot-intent classifier to learn the many-to-one mapping relationship between slots and intents. Chen et al [19] proposed a transformer-based threshold-free multi-intent NLU model, using the high-level encoding of BERT as the intent and slot encoding, providing the model with rich semantic features, and integrating intent encoding information into the slot-filling part. At the same time, it transformed the multi-intent threshold determination problem into an intent number classification problem, used a threshold-free multi-intent determination structure, and improved the performance and generalization ability of the model.
Most of the above multi-intent joint model research have adopted a unidirectional interaction structure from intent to slot. Based on this, in order to further utilize the correlation between intent and slot to improve the overall performance of the model, this paper proposes a multi-intent detection and slot-filling joint model MSBI based on a bidirectional interaction structure. It fuses intent encoding information during slot encoding, and after completing slot decoding, it fuses slot decoding information into the intent decoding part.
2 Model
The structure of the MSBI model proposed in this paper is illustrated in Fig. 2. The MSBI model improves performance by fully exploiting the correlation between intent and slot through a bidirectional interaction structure. Simultaneously, this paper adopts a threshold-free multi-intent determination structure[19], and introduces an intent number classification layer into the model, and uses the CLS vector of the final layer of the BERT[18] encoding network for intent number classification. Moreover, to verify the generalizability of the bidirectional interaction structure between intent and slot proposed in this paper, the MSBI-single model is obtained by eliminating the intent number classification layer based on the MSBI model for single-intent scenarios.
 |
Fig. 2 The structure of the MSBI mode |
2.1 BERT
This paper uses BERT as a shared encoder for intent and slot. For a given sequence of inputs  , BERT's output is the corresponding word vector sequence
, BERT's output is the corresponding word vector sequence  . BERT inserts a specific classification word, CLS, at the beginning of each input sequence, which can extract the feature information of the entire sequence. This paper uses the word vector output by the last layer of the BERT encoding network for further intent encoding and slot encoding. It uses the CLS vector output by the last layer of the BERT encoding network as the input to the intent number classification layer.
. BERT inserts a specific classification word, CLS, at the beginning of each input sequence, which can extract the feature information of the entire sequence. This paper uses the word vector output by the last layer of the BERT encoding network for further intent encoding and slot encoding. It uses the CLS vector output by the last layer of the BERT encoding network as the input to the intent number classification layer.
2.2 Intent Encoding
In the intent encoding part of this paper, BiLSTM[21] and Self-Attention[22] are used to extract sequence information and critical context information, then calculate the attention score and weigh it to get the intent encoding  .
.
BiLSTM is made up of a forward and an inverse LSTM. Assume the input is  , and the forward LSTM extracts features from t1 to tN to produce the hidden state
, and the forward LSTM extracts features from t1 to tN to produce the hidden state  , where h is the number of LSTM hidden units. The inverse LSTM pulls features from tN to t1 in reverse order, yielding the hidden state
, where h is the number of LSTM hidden units. The inverse LSTM pulls features from tN to t1 in reverse order, yielding the hidden state . Finally, HF and HR are combined to obtain the sequence information
. Finally, HF and HR are combined to obtain the sequence information  , where N is the number of input words,
, where N is the number of input words,  is the concatenation operation.
is the concatenation operation.
In the self-attention mechanism, the three matrices Q, K, and V are all produced by multiplying the identical input  by the three transformation matrices
by the three transformation matrices  . First, Q is dotted with K, then divided by
. First, Q is dotted with K, then divided by  (
( is the size of the vectors in Q andK) to prevent the result from being too large, then normalized by softmax. Finally, the normalized values are multiplied by the matrix V to get the Self-Attention output
is the size of the vectors in Q andK) to prevent the result from being too large, then normalized by softmax. Finally, the normalized values are multiplied by the matrix V to get the Self-Attention output 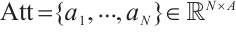 , where A is the output dimension of the Self-Attention mechanism, KT is the transpose ofK, as shown in equation (1).
, where A is the output dimension of the Self-Attention mechanism, KT is the transpose ofK, as shown in equation (1).
 (1)
(1)
This paper splices the output H of BiLSTM with the output Att of the self-attention mechanism, as shown in Eq. (2). The attention score is then calculated and weighted to produce the intent encoding[22], as outlined in Eqs. (3) and (4), where  is the self-attention mechanism score,
is the self-attention mechanism score,  is the matrix parameters to be trained,
is the matrix parameters to be trained,  is the offset, and
is the offset, and  is the intent encoding.
is the intent encoding.
 (2)
(2)
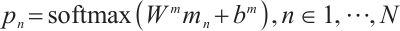 (3)
(3)
 (4)
(4)
2.3 Slot Encoding
As shown in Fig. 3, in the slot encoding part of this paper, BiLSTM is first used for encoding to obtain the encoding matrix 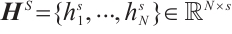 . Then, the intent encoding vector
. Then, the intent encoding vector  is orthogonalized with each vector in the encoding matrix
is orthogonalized with each vector in the encoding matrix  in turn to reduce redundant information[23], as shown in equation (5), where dot() is the dot product operation. Then, we splice the orthogonalized matrix
in turn to reduce redundant information[23], as shown in equation (5), where dot() is the dot product operation. Then, we splice the orthogonalized matrix  with the encoding matrix
with the encoding matrix  to get the slot encoding, as shown in Eq. (6). In this paper, the hyperparameters A and h are set to
to get the slot encoding, as shown in Eq. (6). In this paper, the hyperparameters A and h are set to  , so that the dimension of the intent encoding vector
, so that the dimension of the intent encoding vector  meets the requirements for orthogonalization with the encoding matrix
meets the requirements for orthogonalization with the encoding matrix  , where S is the number of hidden units in the slot-filling part of BiLSTM.
, where S is the number of hidden units in the slot-filling part of BiLSTM.
 |
Fig. 3 The structure of slot encoding |
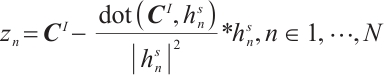 (5)
(5)
 (6)
(6)
2.4 Slot Decoding
In this paper, we use softmax and argmax to decode the slot encoding L in the slot decoding section. First, softmax decoding is used to obtain the slot probability distribution information  of each word, where
of each word, where  is the number of slot labels. Then, argmax is used to get the specific slot value Slot of each word, as shown in equations (7) and (8). Among them argmax() operation is to obtain the index of the maximum value in the input.
is the number of slot labels. Then, argmax is used to get the specific slot value Slot of each word, as shown in equations (7) and (8). Among them argmax() operation is to obtain the index of the maximum value in the input.  is the transformation matrix that needs to be trained, and
is the transformation matrix that needs to be trained, and  is the offset.
is the offset.
 (7)
(7)
 (8)
(8)
2.5 Intent Number Classification Layer
Following Ref.[19], we convert the multi-intent threshold determination problem to an intent number classification problem. For example, suppose the text statements in the training set of the datasets have up to 3 intents. In that case, the intent number classification can be regarded as a 3-classification problem, and its intent number labels are "1", "2", and "3", respectively. This paper uses the CLS vector of the last layer of the BERT encoding network for intent number classification, as shown in equations (9) and (10). Among them,  is the parameter matrix that needs to be trained, and
is the parameter matrix that needs to be trained, and  is the offset. The maximum number of intents can be adjusted according to specific application scenarios or datasets.
is the offset. The maximum number of intents can be adjusted according to specific application scenarios or datasets.  is the index of the predicted intent number category.
is the index of the predicted intent number category.
 (9)
(9)
 (10)
(10)
2.6 Intent Decoding
As shown in Fig. 4, this paper first flattens each word's slot probability distribution information  into
into  . It is spliced with the intent encoding
. It is spliced with the intent encoding  to get the intent encoding
to get the intent encoding 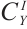 , which fuses slot decoding information. Then,
, which fuses slot decoding information. Then,  is passed through the intent decoding layer to get the intent distribution information
is passed through the intent decoding layer to get the intent distribution information  , where
, where 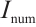 is the number of intent labels. Finally, the specific intent Intent is obtained through the Maxtop() operation on
is the number of intent labels. Finally, the specific intent Intent is obtained through the Maxtop() operation on  and the intent number
and the intent number  , as shown in equations (11), (12), (13), and (14). Among them, flatten() is the flattening operation,
, as shown in equations (11), (12), (13), and (14). Among them, flatten() is the flattening operation,  and
and  are the transformation matrices that need to be trained, LeakyReLU and Sigmod are activation functions, and
are the transformation matrices that need to be trained, LeakyReLU and Sigmod are activation functions, and  and
and  are offsets. The
are offsets. The  operation means taking the index of the top
operation means taking the index of the top  values in
values in  . For example,
. For example,  ,
,  . The final determined intent is
. The final determined intent is  .
.
 |
Fig. 4 The structure of intent decoding |
 (11)
(11)
 (12)
(12)
 (13)
(13)
 (14)
(14)
Because the lengths of the sentences in the data are generally different, it is necessary to set the maximum sentence length Max_len and make N=Max_len a fixed sentence length. Sentences that are less than the maximum sentence length are padded with the [PAD] word that comes with the BERT vocabulary. In future research, we will continue to study design schemes that do not require a fixed sentence length.
In the generalization experiment for the single-intent joint training dataset, since the application scenario is a single-intent scenario, the MSBI-single model does not need the number of intents  to participate in decoding but directly selects the index of the maximum value in
to participate in decoding but directly selects the index of the maximum value in  as a result, as shown in Eq. (15).
as a result, as shown in Eq. (15).
 (15)
(15)
2.7 Jointly Trained Loss Function
2.7.1 MSBI model loss function
This paper adopts a threshold-free multi-intent determination method, which requires the definition of loss functions for the three parts of multi-intent detection, slot filling, and intent number classification, and then joint optimization to update the model parameters. The loss function of multi-intent detection is defined as shown in Eq. (16), where  is the number of intent labels,
is the number of intent labels,  is the predicted value of the intent, and
is the predicted value of the intent, and  is the intent label.
is the intent label.
 (16)
(16)
The loss function for slot filling is defined as shown in Eq. (17), where  is the number of slot labels,
is the number of slot labels,  is the predicted value of the slot,
is the predicted value of the slot,  is the slot label, and N is the number of input words.
is the slot label, and N is the number of input words.
 (17)
(17)
The loss function for intent number classification is as shown in Eq. (18), where  is the maximum number of intents,
is the maximum number of intents,  is the predicted value of the number of intents, and
is the predicted value of the number of intents, and  is the label of the number of intents.
is the label of the number of intents.
 (18)
(18)
The final joint training loss function is defined as shown in Eq. (19), where  ,
,  , and
, and  are hyperparameters.
are hyperparameters.
 (19)
(19)
2.7.2 MSBI-single model loss function
Because the application scenario of the MSBI-single model is a single-intent scenario, it is only necessary to define the loss functions for the two tasks of intent detection and slot filling. The loss function for intent detection is shown in Eq. (20).
 (20)
(20)
The loss function for slot filling is shown in Eq. (21).
 (21)
(21)
The final joint training loss function is shown in Eq. (22).
 (22)
(22)
3 Experimentation and Analysis
3.1 Experimental Datasets
In the multi-intent scenario, this paper conducts experiments using two publicly available multi-intent joint training datasets, MixATIS and MixSNIPS, which were first introduced in Ref.[14]. The MixATIS dataset is based on the ATIS (Airline Travel Information Systems) dataset, widely used for question-answering tasks related to air travel. MixATIS extends the ATIS dataset by synthesizing data for multi-intent scenarios, comprising 13 162 training samples, 759 validation samples, and 828 test samples. The MixSNIPS dataset is based on SNIPS[24], a natural language understanding dataset that includes multiple intent classification tasks. MixSNIPS further extends SNIPS by adding multi-intent tasks across different domains, creating a more diverse dataset for multi-intent scenarios. It contains 39 776 training samples, 2 198 validation samples, and 2 199 test samples.In both datasets, the distribution of sentences with 1, 2, or 3 intents follows a ratio of [0.3, 0.5, 0.2].
In the single-intent scenario, this paper selects SNIPS[24] and CAIS[11], two public single-intent joint training datasets, for experiments. The SNIPS dataset has 13 084 training data, 700 validation data, and 700 test data. CAIS is a Chinese dataset with 7 995 training data, 994 validation data, and 1 012 test data.
In terms of dataset annotation, this paper applies the BIO slot labeling scheme to the MixATIS, MixSNIPS, and SNIPS datasets, while the BIOES slot labeling scheme is employed for the CAIS dataset.
3.2 Experimental Setup
The BERT used in this paper has 12 encoding layers and 12 attention heads, and the dimension of the word vector d is 768. The model optimization uses the AdamW optimizer to optimize the training parameters. Based on experience, this paper sets the hyperparameter  of the loss function on the MixATIS and MixSNIPS datasets. The output dimension A of the Self-Attention mechanism is 384, the number of hidden units h of the BiLSTM for intent encoding is 384, the number of hidden units s of the BiLSTM for slot filling is 768, and the learning rate is
of the loss function on the MixATIS and MixSNIPS datasets. The output dimension A of the Self-Attention mechanism is 384, the number of hidden units h of the BiLSTM for intent encoding is 384, the number of hidden units s of the BiLSTM for slot filling is 768, and the learning rate is  .
.
In terms of experimental evaluation, this paper follows the methods outlined in Refs. [13,19]. On both the multi-intent and single-intent joint training datasets, the evaluation metrics used are intent detection accuracy Intent(Acc), slot filling F1 score Slot(F1), and overall sentence accuracy Overall(Acc), as shown in equations (23),(24) and (25), respectively. Here, Intent_true denotes the number of correctly detected intent samples, Sample represents the total number of samples,  and
and  refer to the precision and recall of the model in the slot filling task, and Total_true represents the number of samples where both the intent and slot labels are correctly identified in the sentence.
refer to the precision and recall of the model in the slot filling task, and Total_true represents the number of samples where both the intent and slot labels are correctly identified in the sentence.
 (23)
(23)
 (24)
(24)
 (25)
(25)
3.3 Baselines
On the multi-intent joint training dataset, this paper compares the MSBI model with the following baselines.
1) AGIF: Qin et al[14] introduced an intent-slot graph interaction layer to extract relevant intent information and provide fine-grained intent information integration for slot filling, establishing a correlation between slots and intents.
2) GL-GIN: Qin et al[15] proposed a non-autoregressive multi-intent joint model that models slot dependencies by introducing a local slot-aware graph interaction layer.
3) SDJN: Chen et al [16] established a self-distillation auxiliary loop to facilitate interaction between intents and slots.
4) SLIM: Cai et al [17] proposed a BERT-based multi-intent joint model and introduced a slot-intent classifier to learn the many-to-one mapping relationship between slots and intents.
5) TFMN: Chen et al[19] proposed a Transformer-based threshold-free multi-intent NLU model that transforms the multi-intent threshold determination problem into an intent number classification problem, eliminating the dependence on manually set thresholds for multi-intent determination.
In the generalization experiments on the single-intent joint training dataset, this paper compares the MSBI-single model with the following baselines.
1) BiAss-Gate: Wang et al[10] put forward a bidirectional interaction model for intent and slot based on a gating mechanism, which conducts bidirectional interaction through shared parameters.
2) CM-Net: Liu et al [11] proposed a joint model based on collaborative memory and also annotated a Chinese joint training dataset, CAIS.
3) Word: Teng et al [12] proposed a Chinese joint model based on multi-level word adapters. The model is provided with character-level information through multi-level character adapters and conducts unidirectional interaction from intent to slot, fusing intent decoding details for part of the slot filling.
4) PKJL: Hou et al [13] proposed a joint model based on prior knowledge, which constituted previous knowledge of the information integration unit by extracting the relationship between intent labels and slot labels, further improving model performance through prior knowledge.
To ensure a fair comparison between different models, we evaluate the performance of the aforementioned baseline models using the three evaluation metrics defined in Subsection 3.2.
3.4 Experimental Results
As shown in Table 1, compared with the baseline model TFMN, which has the best model performance, the MSBI model proposed in this paper has improved Overall(Acc) by 1% and Intent(Acc) by 2.2% on the MixATIS dataset. On the MixSNIPS dataset, Overall(Acc) has improved by 1.2%, and Slot(F1) has been enhanced by 0.6%.
On the MixATIS dataset, the Slot(F1) of the MSBI model proposed in this paper is slightly lower than the TFMN model, but on the MixSNIPS dataset, the Slot(F1) of the MSBI model is higher than the TFMN model. The reason for this may be that the MixATIS training set has 111 slot labels, compared to the MixSNIPS training set, which only has 72 slot labels. The MixATIS dataset has more slot labels and is more finely divided, and the total amount of MixATIS training data is also less than MixSNIPS. This may make the slot-filling task on the MixATIS dataset more difficult than that on the MixSNIPS dataset, further leading to the slightly lower slot-filling performance of the MSBI model on the MixATIS dataset and the higher slot-filling performance on the MixSNIPS dataset than that on the TFMN model.
Overall, through the comparative experiments of the MSBI model and the baseline model on the MixATIS dataset and the MixSNIPS dataset, it can be seen that the MSBI model has achieved excellent results on both multi-intent joint training datasets, and the overall performance of the model has been further improved compared to the multi-intent joint models in recent years.
Comparative experimental results of MixATIS and MixSNIPS datasets (unit:%)
3.5 Experimental Analysis
3.5.1 Analysis of the effectiveness of bidirectional interaction structure
To validate the effectiveness of the proposed bidirectional interaction structure of intent and slot in this paper, we conducted an ablation study on the bidirectional interaction structure of the MSBI model on the MixATIS dataset, obtaining "w/o slot to intent" and "w/o intent to slot", in which "w/o slot to intent" only involves unidirectional interaction from intent to slot, and "w/o intent to slot" only involves unidirectional interaction from slot to intent.
As shown in Table 2, on the MixATIS dataset, compared with "w/o slot to intent", the MSBI model has improved Overall(Acc) by 6.3%, Intent(Acc) by 3.3%, and Slot(F1) by 2.5%. Compared with "w/o intent to slot", the MSBI model has improved Overall(Acc) by 3.5%, Intent(Acc) by 2.3%, and Slot(F1) by 0.5%. The results of the ablation experiment on the bidirectional interaction structure on the MixATIS dataset show that the performance of the model of the bidirectional interaction structure of intent and slot proposed in this paper is better than the unidirectional interaction structure from intent to slot and from slot to intent, which verifies the effectiveness of the bidirectional interaction structure proposed in this paper.
Results of MSBI model ablation experiments on the MixATIS dataset (unit:%)
3.5.2 Analysis of the effectiveness of encoding structure
This paper splices BiLSTM and the Self-Attention mechanism for the intent encoding part based on the BERT model structure. It splices BiLSTM for the slot encoding part so that the model can further extract the relevant feature information of the sentence. To further verify the effectiveness of BiLSTM, the Self-Attention mechanism in the intent encoding part, and BiLSTM in the slot encoding part, this paper conducted ablation experiments on these three encoding structures on the MixATIS dataset, respectively. Among them, "w/o intent Bilstm" is obtained by ablating BiLSTM in the intent encoding part, "w/o intent Attention" is obtained by ablating the Self-Attention mechanism, and "w/o slot Bilstm" is obtained by ablating BiLSTM in the slot encoding part.
As shown in Table 3, the MSBI model, compared with "w/o intent Bilstm" and "w/o intent Attention" respectively, has increased Overall(Acc) by 3.1% and 4.5%, Intent(Acc) by 2.5% and 2.8%, and Slot(F1) by 0.4% and 1%. This suggests that both BiLSTM and Self-Attention in the intent encoding part of the MSBI model have a significant impact on enhancing the model's performance. In comparison to "w/o slot Bilstm", the MSBI model has increased Overall(Acc) by 3.6%, Intent(Acc) by 2.8%, and Slot(F1) by 0.5%. This suggests that the BiLSTM in the slot encoding part of the MSBI model also plays a significant role in enhancing the model's performance. The ablation experiment of the model's encoding structure validates the effectiveness of the encoding structure proposed in this paper.
Results of encoding structure ablation experiments on the MixATIS dataset (unit:%)
3.5.3 Analysis of generalization on single-intent dataset
To validate the generalization of the bidirectional interaction structure proposed in this paper, the MSBI-single model is proposed based on the MSBI model for single-intent scenarios, and comparative experiments are carried out on the SNIPS and CAIS, which are two single-intent joint training datasets.
As shown in Table 4, on the SNIPS dataset, compared with the PKJL model, the MSBI-single model has improved Overall(Acc) by 4.9% and Slot(F1) by 2.3%. Compared with the BiAss-Gate model in Ref. [10], MSBI-single has improved Overall(Acc) by 8.9%, Intent(Acc) by 0.4%, and Slot(F1) by 3.4%. This shows that the bidirectional interaction structure proposed in this paper is superior to the shared parameter bidirectional interaction structure in Ref.[10] and can better utilize their correlation. On the CAIS dataset, compared with the Word model, the MSBI-single model has improved Overall(Acc) by 2.3%. Compared with the PKJL model, Overall(Acc) has improved by 4%, Intent(Acc) has been enhanced by 0.4%, and Slot(F1) has improved by 0.3%.
The experimental results show that the bidirectional interaction structure proposed in this paper can also achieve excellent performance in two single-intent scenarios, demonstrating good generalizability.
Experimental results of SNIPS and CAIS datasets (unit:%)
4 Discussion
Although current multi-intent joint models have achieved good results, there are still shortcomings in fully exploiting the correlation between intent and slot. Existing studies typically adopt a unidirectional interaction structure from intent to slot, improving model performance by incorporating intent information during the slot-filling phase. However, the lack of guidance from slot information during the intent detection phase limits the model's ability to capture the complex interactions between intent and slot. This unidirectional structure may have inherent limitations in effectively modeling these dependencies.
In contrast, the multi-intent recognition and slot-filling joint model based on the bidirectional interaction structure (MSBI) proposed in this paper shows, through experimental results in Section 3, that the bidirectional interaction mechanism improves the performance of intent detection and slot-filling, demonstrating its effectiveness and advantages. The performance improvement stems from the mechanism's ability to capture the mutual influence between intent and slot information. Specifically, it integrates intent information during slot encoding and feeds slot decoding information back into the intent decoding phase, forming a complete bidirectional information flow. Compared with unidirectional models, this structure more accurately captures the complex relationships between intent and slots, significantly improving performance in multi-intent recognition and slot filling.
5 Conclusion
This work proposes a joint model of multi-intent detection and slot filling based on a bidirectional interaction structure, MSBI. The MSBI model fuses intent encoding information in the slot encoding part. After completing slot decoding, it fuses slot decoding information for the intent decoding part, realizing bidirectional interaction between intent and slot and further improving the overall performance of the model by utilizing their correlation in the intent detection part. Compared with the multi-intent joint model TFMN in recent years, the overall accuracy of sentences on the MixATIS dataset has increased by 1%, and the accuracy of intent detection has increased by 2.2%. On the MixSNIPS dataset, the overall accuracy of sentences has increased by 1.2%, and the F1 value of slot filling has increased by 0.6%. The ablation experiment of the bidirectional interaction structure on the MixATIS dataset proves that the bidirectional interaction structure of intent and slot proposed in this paper is superior to the unidirectional interaction structure from intent to slot and from slot to intent and can better utilize their correlation to improve the performance of the model further. The ablation experiment of the model encoding structure proves that both BiLSTM and Self-Attention spliced in the intent encoding part of the MSBI model and BiLSTM spliced in the slot encoding part have a positive effect on improving the overall performance of the model. In addition, to verify the generalization of the bidirectional interaction structure proposed in this paper, the MSBI-single model, a single-intent joint model for single-intent application scenarios, is proposed based on the MSBI model. It also achieves excellent performance on the CAIS and SNIPS, two public single-intent joint training datasets.
In the future, we will try to further improve the performance of the model from the following three aspects: (1) Based on the model in this paper, we will study the design scheme that does not need to fix the sentence length in the intent decoding part. (2) Obtain prior knowledge by calculating the probability distribution relationship of intent labels and slot labels in the dataset and integrate prior knowledge during the encoding process. (3) Use the method of prefix prompts to fine-tune the existing model further. During the fine-tuning process, add prompt information at the head of the text data to further improve the overall performance of the model.
References
- Weld H, Huang X, Long S, et al. A survey of joint intent detection and slot filling models in natural language understanding[J]. ACM Computing Surveys, 2022, 55(8): 1-38. [Google Scholar]
- Qin L B, Xie T B, Che W X, et al. A survey on spoken language understanding: Recent advances and new frontiers[EB/OL]. [2021-03-12].https://arxiv.org/abs/2103.03095v2. [Google Scholar]
- Reimers N, Gurevych I. Optimal hyperparameters for deep LSTM-networks for sequence labeling tasks[EB/OL]. [2020-01-12]. https://arxiv.org/abs/1707.06799v2. [Google Scholar]
- McCallum A, Freitag D, Pereira F C N. Maximum entropy Markov models for information extraction and segmentation[C]//ICML. 2000, 17: 591-598. [Google Scholar]
- Cortes C, Vapnik V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273-297. [Google Scholar]
- Ma Q W, Yuan C Y, Zhou W, et al .Label-specific dual graph neural network for multi-label text classification[C]//Proc of the 59th Ann Meeting of the Assoc for Computational Ling and the 11th Int Joint Conf on Nat Language Processing (Vol 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2021: 3855-3864. [Google Scholar]
- Liu W F, Pang J M, Li N, et al. Research on multi-label text classification method based on tALBERT-CNN[J]. International Journal of Computational Intelligence Systems, 2021, 14(1): 201. [CrossRef] [Google Scholar]
- Goo C W, Gao G, Hsu Y K, et al .Slot-gated modeling for joint slot filling and intent prediction[C]//Proc of the 2018 Conf of the North American Chapter of the Assoc for Comp Ling: Human Language Technologies, Vol 2 (Short Papers). Stroudsburg: Association for Computational Linguistics, 2018: 753-757. [Google Scholar]
- Qin L B, Che W X, Li Y M, et al. A stack-propagation framework with token-level intent detection for spoken language understanding[EB/OL]. [2019-02-12].https://arxiv.org/abs/1909.02188v1. [Google Scholar]
- Wang L H, Yang W Z, Yao M, et al. A bidirectional association model for intention recognition and semantic slot filling[J]. Computer Engineering and Applications, 2021, 57 (3): 196-202. [Google Scholar]
- Liu Y J, Meng F D, Zhang J C, et al. CM-net: A novel collaborative memory network for spoken language understanding[EB/OL]. [2019-02-12].https://arxiv.org/abs/1909.06937v1. [Google Scholar]
- Teng D C, Qin L B, Che W X, et al .Injecting word information with multi-level word adapter for Chinese spoken language understanding[C]//IEEE Inter Conf on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2021: 8188-8192. [Google Scholar]
- Hou C N, Li J P, Yu H, et al .Prior knowledge modeling for joint intent detection and slot filling[C]//Machine Learning, Multi Agent and Cyber Physical Systems. Singapore: World Scientific, 2023: 3-10. [Google Scholar]
- Qin L B, Xu X, Che W X, et al .AGIF: An adaptive graph-interactive framework for joint multiple intent detection and slot filling[C]//Findings of the Association for Computational Linguistics: EMNLP 2020. Stroudsburg: Association for Computational Linguistics, 2020: 1807-1816. [Google Scholar]
- Qin L B, Wei F X, Xie T B, et al .GL-GIN: Fast and accurate non-autoregressive model for joint multiple intent detection and slot filling[C]//Proc of the 59th Ann Meeting of the Asso for Comp Ling and the 11th Inter Joint Conf on Natural Language Processing (Vol 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2021: 178-188. [Google Scholar]
- Chen L S, Zhou P L, Zou Y X. Joint multiple intent detection and slot filling via self-distillation[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2022: 7612-7616. [Google Scholar]
- Cai F Y, Zhou W H, Mi F, et al .Slim: Explicit slot-intent mapping with Bert for joint multi-intent detection and slot filling[C]//IEEE Inter Conf on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE, 2022: 7607-7611. [Google Scholar]
- Devlin J, Chang M, Lee K, et al .BERT: Pre-training of deep bidirectional transformers for language understanding[C]//Proc of the 2019 Conf of the North American Chapter of the Asso for Comp Ling: Human Language Technologies. Stroudsburg: Association for Computational Linguistics,2019: 4171-4186. [Google Scholar]
- Chen L S, Chen N, Zou Y X, et al .A transformer-based threshold-free framework for multi-intent NLU[C]//Proceedings of the 29th International Conference on Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2022: 7187-7192. [Google Scholar]
- Vaswani A, Shazeer N, Parmar N, et al .Attention is all you need[C]. Proceedings of the 31th International Conference on Neural Information Processing Systems. New York: AMC, 2017: 6000-6010. [Google Scholar]
- Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. [CrossRef] [Google Scholar]
- Zhong V, Xiong C M, Socher R. Global-locally self-attentive encoder for dialogue state tracking[C]//Proc of the 56th Ann Meeting of the Assoc for Comp Ling (Vol 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2018: 1458-1467. [Google Scholar]
- Li W B, Wang Z Y, Wu Y F. A unified neural network model for readability assessment with feature projection and length-balanced loss[EB/OL]. [2020-01-12].https://arxiv.org/abs/2210.10305v2. [Google Scholar]
- Coucke A, Saade A, Ball A, et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces[EB/OL]. [2020-01-12].https://arxiv.org/abs/1805.10190v3. [Google Scholar]
All Tables
Results of encoding structure ablation experiments on the MixATIS dataset (unit:%)
All Figures
|
Fig. 1 Example of intent detection and slot filling |
| In the text | |
|
Fig. 2 The structure of the MSBI mode |
| In the text | |
|
Fig. 3 The structure of slot encoding |
| In the text | |
|
Fig. 4 The structure of intent decoding |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.