| Issue |
Wuhan Univ. J. Nat. Sci.
Volume 30, Number 1, February 2025
|
|
|---|---|---|
| Page(s) | 1 - 20 | |
| DOI | https://doi.org/10.1051/wujns/2025301001 | |
| Published online | 12 March 2025 | |
Computer Science
CLC number: TP183
A Survey of Adversarial Examples in Computer Vision: Attack, Defense, and Beyond
计算机视觉领域中对抗样本的综述:攻击、防御及其他
1 School of Computer Science, Wuhan University, Wuhan 430072, Hubei, China
2 National Engineering Research Center for Multimedia Software (NERCMS), Wuhan University, Wuhan 430072, Hubei, China
3 Key Laboratory of Multimedia and Network Communication Engineering, Hubei Province, Wuhan University, Wuhan 430072, Hubei, China
4 School of Cyber Science and Engineering, Wuhan University, Wuhan 430072, Hubei, China
† Corresponding author. E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
12
July
2024
Abstract
Recent years have witnessed the ever-increasing performance of Deep Neural Networks (DNNs) in computer vision tasks. However, researchers have identified a potential vulnerability: carefully crafted adversarial examples can easily mislead DNNs into incorrect behavior via the injection of imperceptible modification to the input data. In this survey, we focus on (1) adversarial attack algorithms to generate adversarial examples, (2) adversarial defense techniques to secure DNNs against adversarial examples, and (3) important problems in the realm of adversarial examples beyond attack and defense, including the theoretical explanations, trade-off issues and benign attacks in adversarial examples. Additionally, we draw a brief comparison between recently published surveys on adversarial examples, and identify the future directions for the research of adversarial examples, such as the generalization of methods and the understanding of transferability, that might be solutions to the open problems in this field.
摘要
近年来,深度神经网络(DNNs)在计算机视觉任务中的表现日益出色。然而,研究人员发现了一个潜在的漏洞:精心设计的对抗样本很容易通过对输入数据进行不可察觉的修改而误导 DNNs 做出错误行为。在本综述中,我们重点关注(1)对抗攻击算法以生成对抗样本,(2)对抗防御技术以保护 DNNs 免受对抗样本攻击,以及(3)对抗样本领域中除攻击和防御之外的重要问题,包括对抗样本的理论解释、折中问题以及良性攻击。此外,我们对最近发表的对抗样本综述进行了简要比较,并确定了对抗样本研究的未来方向,如方法的跨域泛化、对可迁移性的理解等,这些方向可能会解决该领域的未解决问题。
Key words: computer vision / adversarial examples / adversarial attack / adversarial defense
关键字 : 计算机视觉 / 对抗样本 / 对抗攻击 / 对抗防御
Cite this article: XU Keyizhi, LU Yajuan, WANG Zhongyuan, et al. A Survey of Adversarial Examples in Computer Vision: Attack, Defense, and Beyond[J]. Wuhan Univ J of Nat Sci, 2025, 30(1): 1-20.
Biography: XU Keyizhi, male, Master candidate, research direction: AI security, adversarial examples. E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Foundation item: Supported by the National Natural Science Foundation of China(U1903214, 62372339, 62371350, 61876135), the Ministry of Education Industry-University Cooperative Education Project(202102246004, 220800006041043, 202002142012), and the Fundamental Research Funds for the Central Universities (2042023kf1033)
© Wuhan University 2025
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
0 Introduction
With the advent of novel neural network architectures like ResNet[1] and Transformers[2], Deep Neural Networks (DNNs) have already achieved impressive performance in various computer vision tasks. However, the effectiveness of DNNs is not always guaranteed, especially when the setup involves a malicious adversary who attempts to corrupt the inference of the network. This scenario was first considered by Szegedy et al[3], showing that carefully designed, slight perturbations in the input data of DNNs can largely affect their outputs. They name such input data as adversarial examples, and the process of modification to the input data as adversarial attacks[4-6].
Kurakin et al[7] demonstrated that threats of adversarial attacks also exist in the physical world. In the physical world, adversarial examples are instances where real objects are modified in appearance or structure in such a way that they can deceive DNN-based systems, especially visual systems. Adversarial attacks in the physical world and those in the digital domain differ in execution conditions and forms, but these two attacks are similar in core algorithmic principles, mainly using various optimization methods to pursue the goal of misleading models. These discoveries of adversarial examples ring a wake-up bell for researchers in computer vision: high-performance DNNs are susceptible to adversarial attacks, which raises concerns about their deployment in real scenarios.
In a bid to ensure the performance of DNNs under adversarial attacks, numerous works have been devoted to the study of adversarial defenses[8-10]. Some of them focus on the adversarial robustness of models by improving their intrinsic capacity to correctly address adversarial examples[8,11], while others turn to external strategies by pre-processing the adversarial examples to make them harmless to DNNs[10,12,13].
Besides, the impact of adversarial examples has actually gone far beyond the wrestling of attack and defense as a security issue of computer vision models, so we will discuss some important issues related to adversarial examples to provide insights from multiple perspectives.
Adversarial example is a large research topic involving theoretical, empirical, and methodological studies spanning a wide range of computer vision. Existing surveys on adversarial examples[14-19] have already presented all-around panorama of adversarial attacks and defenses. This section provides a concise review of previous surveys on adversarial examples and draws a comparison between them in Table 1. We give relatively objective comments on each of them and explain the reasons below.
Serban et al[14] made an in-depth survey into adversarial examples. They started from a machine learning perspective and delved into several important problems of this topic. However, some terminologies in this survey, especially the name of methods, are not in line with other main literature in adversarial research. Machado et al[15] studied adversarial examples from the defender's perspective. They classified adversarial attacks by 3 standards and divided defenses into proactive and reactive defenses. Additionally, they pointed out some principles for designing defense methods. Long et al[16] focused on adversarial attacks. They made impressive visualizations of existing attack methods. Also, the analysis and research directions are well-concluded in this survey. However, the taxonomy is relatively simplistic and does not explicitly distinguish between black-box and white-box methods. Wang et al[17] made a fine classification for attacks and defenses, which was the most comprehensive among all the surveys investigated, but the related discussions were limited. Li et al[18] looked into the research of adversarial attacks in both 2D and 3D computer vision. They focused on additional aspects of adversarial attacks from previous surveys, especially the application of attacks in the physical world. Costa et al[19] not only considered traditional models but also investigated adversarial attacks and defenses for Vision Transformers. Moreover, they compared the performance of different methods.
However, we notice that the taxonomies vary in existing surveys, lacking a harmonized classification standard. Hence in this survey, we adopt the most recognized standards when constructing our taxonomies. And different from the previous surveys, our work is aimed at providing a glimpse of the research of adversarial examples and allowing researchers to get a quick notion of this field. To this end, we only present the most classic, representative and illustrative related works to form a well-structured taxonomy of adversarial attacks and defenses. Therefore, some related works might be purposefully omitted in this survey. For example, highly ad-hoc designs of attacks or defenses on specific tasks will not be discussed, for their impact is limited to a certain smaller branch of computer vision.
To conclude, this survey makes the following contributions:
● We carry out a concise survey in the field of adversarial examples. It provides an overview of adversarial attacks and defenses.
● We discuss some important issues related to adversarial examples beyond attack and defense, which helps to better understand this topic.
● We identify the future directions for the research of adversarial examples that might be solutions to the open problems in this field.
Different surveys on adversarial examples
1 Preliminaries
In order to clarify the concept of adversarial attacks and defenses, we first consider the non-adversarial setup in a classification task. Given a measurable instance space  where
where  is the input data space and
is the input data space and  is the label space, a neural network
is the label space, a neural network  is defined as a function that maps the input data space into the label space, and
is defined as a function that maps the input data space into the label space, and  represent the parameters of the network. Given a loss function
represent the parameters of the network. Given a loss function  that evaluates the performance of the network parameters on the data, the training process of the network solves the minimization problem to acquire the optimized parameters
that evaluates the performance of the network parameters on the data, the training process of the network solves the minimization problem to acquire the optimized parameters  :
:
 (1)
(1)
A well-trained DNN  can usually achieve rather high performance on test data. However, the existence of adversarial examples raises doubts about the previous assumption. The adversarial example
can usually achieve rather high performance on test data. However, the existence of adversarial examples raises doubts about the previous assumption. The adversarial example  of a clean data sample
of a clean data sample  is found by the following optimization problem:
is found by the following optimization problem:
 (2)
(2)
where  is the adversarial bound, a small neighboring area of
is the adversarial bound, a small neighboring area of  . The process above to generate adversarial examples is called adversarial attacks. It is often implemented by adding a small perturbation
. The process above to generate adversarial examples is called adversarial attacks. It is often implemented by adding a small perturbation  to the input data
to the input data  , and indicates
, and indicates 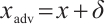 (Fig. 1). Adversarial attacks can greatly challenge the effectiveness of the DNN models, fooling them into making incorrect predictions.
(Fig. 1). Adversarial attacks can greatly challenge the effectiveness of the DNN models, fooling them into making incorrect predictions.
 |
Fig. 1 An example showing the implementation of adversarial attacks |
The impact of adversarial attacks on the effectiveness of DNN models is not only in the incorrect predictions made for classification problems, but also has a great impact on computer vision fields such as object detection, face recognition, semantic segmentation, and visual object tracking[20]. Metzen et al[21] demonstrated that perturbations in adversarial examples can deceive DNN, thereby severely damaging the predicted segmentation of images. Xie et al[22] generated adversarial examples for semantic segmentation and object detection by optimizing the loss function and tested the generated examples to deceive various deep learning-based segmentation and detection methods. Kurakin et al[3] demonstrated that most existing machine learning classifiers are very susceptible to slightly modified adversarial samples, causing machine learning classifiers to misclassify them, and this is also true in the field of facial recognition. Pony et al[23] introduced a manipulation scheme of flicker time perturbations to fool video classifiers to mislead tracking algorithms, thereby achieving a high deception rate.
It can be seen that adversarial attacks generated by adversarial examples have wide applications in the field of computer vision. Adversarial attacks pose a real threat to deep learning in practice, especially in safety and security-critical applications.
As a countermeasure, adverarial defenses refer to techniques and strategies developed to protect DNN models from adversarial attacks. These defenses are crucial for ensuring the robustness and reliability of DNN systems, particularly in critical applications such as autonomous driving[24], healthcare[25], and access control[26].
2 Adversarial Attacks
This section provides a comprehensive introduction to the taxonomy of adversarial attacks, followed by a detailed examination of representative attack algorithms. Initially, we define the classification systems of adversarial attacks to establish a foundational understanding for the reader. Subsequently, we will explore several classic and representative adversarial attack algorithms, and systematically categorize them according to the previous taxonomy.
2.1 Taxonomy
There have been numerous works that attempt to categorize adversarial attacks in computer vision, but the standards vary a lot. Some of them simply categorize them into different types using a single standard, while others consider multiple standards to reflect different properties of adversarial attacks. In this survey, we adopt the classification method proposed in the literature[18,24,27-37] and combine the research experience and understanding of more attack algorithms, such as fast gradient sign method (FGSM), projected gradient descent (PGD), DeepFool, etc., to review the current adversarial attack technology. This framework covers most attack algorithms and includes state-of-the-art attack algorithms (Fig. 2). Specifically, we categorize the adversarial attacks by 4 different standards, i.e., adversarial targets, adversarial knowledge, perturbation structure and adversarial bounds.
 |
Fig. 2 The taxonomy of adversarial attacks |
2.1.1 Adversarial targets
As previously stated, adversarial attacks mislead DNNs into incorrect predictions, which can be divided into different mistakes according to the target of the attack. Most attacks are untargeted attacks, where the adversary does not care which class the prediction belongs to, as long as the network yields an incorrect result; in such a case, the attacker follows the standard formulation (Eq. (1)) and maximizes the . Differently, in a targeted attack, the adversary expects the DNN to produce the specific result he wants, which we denote as
. Differently, in a targeted attack, the adversary expects the DNN to produce the specific result he wants, which we denote as  ; in such a case, the attacker solves the following minimization:
; in such a case, the attacker solves the following minimization:
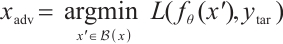 (3)
(3)
The schematic figure of targeted and untargeted attacks is shown in Fig. 3. Most attack algorithms are compatible with the formulation of both targeted and untargeted attacks, while some attack algorithms are proposed for either targeted or untargeted attacks.
 |
Fig. 3 A schematic diagram of untargeted attacks (a) and targeted attacks (b) in the 2D feature space
|








2.1.2 Adversarial knowledge
Adversarial attacks on DNN models can be systematically categorized based on the degree of knowledge the attacker possesses about the target model, i.e., white-box, black-box, and gray-box attacks (Fig. 4).
 |
Fig. 4 A schematic figure of attacks with different adversarial knowledge |
White-box attacks represent scenarios where the attacker has complete knowledge of the target model. This includes access to the model's architecture, parameters, and gradients. Such comprehensive knowledge allows the attacker to craft highly effective and targeted adversarial examples.
Black-box attacks assume that the attacker has no direct access to the target model's internal details, such as its architecture or parameters. Instead, the attacker must rely on querying the model and observing its outputs to infer information and create adversarial examples. Black-box attacks can be further divided into query-based and transfer-based attacks. Query-based attacks[27] approximate gradients by repeatedly querying the model and using the output probabilities or labels to construct adversarial examples. Transfer-based attacks[28] exploit the transferability property of adversarial examples, where an example crafted to deceive one model may also deceive another model. This method involves generating adversarial examples using a substitute model and applying them to the target model.
Gray-box attacks occupy an intermediate position between white-box and black-box attacks, where the attacker has partial knowledge of the target model. In some literatures[18], this category is separately considered, while there are hardly attack algorithms initially designed under this setting. In most cases, attackers apply some techniques to transform the problem into white-box attacks, or simply apply black-box attacks.
2.1.3 Perturbation structures
Adversarial attacks can also be categorized based on the structure of the perturbations introduced to the input data. This classification focuses on the nature and characteristics of the modifications applied to the input, providing a nuanced understanding of how different perturbations impact model performance and robustness. The primary categories of adversarial attacks based on perturbation structure are noise-based attacks, spatial transformation attacks, patch-based attacks, and semantic attacks (Fig. 5).
 |
Fig. 5 Different perturbation structures of adversarial attacks |
Noise-based attacks involve adding small, often imperceptible perturbations to the input data. These perturbations are carefully crafted to be subtle enough to avoid detection by human observers while significantly affecting the model's predictions. Most gradient-based white-box attacks like FGSM[4], PGD[6], and DeepFool[38] fall in this category. These attacks primarily focus on altering pixel values or data points in a high-dimensional space, preserving the original structure of the input while inducing misclassifications.
Spatial transformation attacks manipulate the input through transformations in its geometric properties. They alter the spatial arrangement of its components, which do not merely add noise but instead modify the geometric structure of the input[29]. Spatial transformation attacks exploit the model's sensitivity to the spatial arrangement of input features, causing misclassifications without significant changes to pixel values.
Patch-based attacks[30] place a visually inconspicuous patch on the input image, which can cause the model to misclassify the entire image despite the patch occupying only a small portion of it. This type of attack is more applicable in the physical world[24,31] by sticking printed patches on objects to fool DNN-based systems.
Semantic attacks generate adversarial examples by altering the input in a way that changes its semantic meaning while maintaining perceptual similarity. These attacks involve more complex modifications compared to noise-based or spatial transformation attacks and often leverage higher-level features. One approach involves using Generative Adversarial Networks (GANs)[32] to generate realistic adversarial examples[33].
2.1.4 Adversarial bounds
Adversarial attacks can also be categorized based on the perturbation bounds, which refer to the constraints imposed on the modifications applied to the input data, i.e.,  in Equations (1) and (2). The primary categories based on perturbation bounds are norm-bounded attacks, perceptual-bounded attacks, and unrestricted attacks.
in Equations (1) and (2). The primary categories based on perturbation bounds are norm-bounded attacks, perceptual-bounded attacks, and unrestricted attacks.
Norm-bounded attacks impose specific mathematical constraints on the perturbations, typically using  norms to measure the magnitude of the changes. The most common norms used are the
norms to measure the magnitude of the changes. The most common norms used are the  ,
,  and
and  norms, each defining a different type of constraint.
norms, each defining a different type of constraint.  -norm attacks[34] require
-norm attacks[34] require  and limit the number of modified pixels or features in the input, aiming to achieve misclassification by altering the smallest possible number of elements.
and limit the number of modified pixels or features in the input, aiming to achieve misclassification by altering the smallest possible number of elements.  -norm attacks[5], on the other hand, constrain the Euclidean distance between the original and perturbed inputs, i.e.,
-norm attacks[5], on the other hand, constrain the Euclidean distance between the original and perturbed inputs, i.e.,  , ensuring that the perturbations are less noticeable. Lastly,
, ensuring that the perturbations are less noticeable. Lastly,  -norm attacks which require
-norm attacks which require  limit the maximum change to any individual pixel or feature, ensuring that each modification is bounded by a predefined threshold
limit the maximum change to any individual pixel or feature, ensuring that each modification is bounded by a predefined threshold  . The FGSM[4] is a well-known example, where perturbations are added in the direction of the gradient of the loss function, constrained by an
. The FGSM[4] is a well-known example, where perturbations are added in the direction of the gradient of the loss function, constrained by an  -norm bound.
-norm bound.
Perceptual-bounded attacks aim to create perturbations that are imperceptible to human observers. These attacks focus on maintaining the visual or semantic integrity of the input data while still causing misclassification. The constraints in these attacks are typically based on perceptual metrics rather than strict mathematical norms. One approach is the use of Structural Similarity Index (SSIM)[35] to constrain perturbations, ensuring that the altered image remains visually similar to the original. The SSIM metric considers luminance, contrast, and structure to evaluate perceptual similarity. Other methods involve using Perceptual Adversarial Robustness (PAR) metrics, such as Learned Perceptual Image Patch Similarity (LPIPS)[36] and perceptual color distance[28].
Unrestricted attacks do not impose explicit constraints on the perturbations. Instead, they aim to produce adversarial examples that significantly alter the input data while maintaining a high degree of realism or semantic validity. For example, adversarial examples generated by GANs[37] are not confined by traditional norm constraints, which can induce misclassification while appearing indistinguishable from legitimate inputs. Another approach involves creating physical adversarial examples, where physical objects or modifications cause models to misclassify inputs when captured by cameras.
2.2 Representative Attack Algorithms
The landscape of adversarial attack algorithms is vast and diverse, reflecting the complexity and evolving nature of the field of computer vision. Some of the most notable adversarial attack methods include the FGSM[4], PGD[6], Carlini & Wagner (C&W)[5] attack, and various other forms of attacks. Each of these methods employs distinct techniques and operates under different assumptions about the attacker's knowledge and capabilities. This diversity makes it challenging to categorize these attacks using a single standard specified in the previous section. Each of them highlights unique aspects of the attacks, but fails to encapsulate the full spectrum of their characteristics comprehensively. Consequently, a multifaceted approach is often necessary to understand the nature of existing attack algorithms: we list the most representative attack algorithms in Table 2, and mark their classification using the standards of adversarial targets, adversarial knowledge, perturbation structures and adversarial bounds.
Representative adversarial attack methods
3 Adversarial Defenses
This section offers an in-depth overview of the classification frameworks of adversarial defense strategies, followed by a thorough list of representative defense algorithms. We will start by outlining the various classification schemes of adversarial defenses to provide a solid grounding for the reader. Then, we will delve into several illustrative adversarial defense algorithms, systematically organizing them according to the previously defined taxonomy.
3.1 Taxonomy
In this survey, we adopt the classification methods of adversarial defense proposed in Refs. [6,8,63-70] and combine the understanding of more defense algorithms (Diffpure, MILP, Defense-GAN, etc.), and propose the following taxonomy to classify existing adversarial defenses, as shown in Fig. 6. Specifically, we divide adversarial defenses into five main categories: adversarial training, robust network design, input transformation, certified defenses, and ensemble defenses. In the following sections, we provide detailed descriptions for each of them.
 |
Fig. 6 Taxonomy of adversarial defenses |
3.1.1 Adversarial training
Adversarial training[6] is a technique that involves augmenting the training dataset with adversarial examples, which are intentionally crafted inputs designed to deceive the model. The model is then trained on both the original and adversarially perturbed data, enhancing its robustness to such attacks. This method improves the model's ability to generalize to unseen adversarial attacks, thereby making it more resilient in real-world applications.
There has been significant research interest in developing more robust adversarial training methods in the field[63]. These advanced techniques aim to enhance the robustness of models beyond the basic adversarial training[6] by incorporating various strategies such as employing different loss functions and revisiting misclassified samples. These methods strive to create models that can withstand a broader range of adversarial attacks, thereby improving their reliability and security.
Despite its effectiveness, adversarial training is computationally intensive. It often requires the continuous generation of new adversarial examples as the model evolves during training. This process can be time-consuming and resource-demanding, leading to significant overheads in terms of computational power and training time. To address these challenges, fast adversarial training[64] has emerged as a critical area of research. This approach seeks to reduce the computational burden by optimizing the process of generating adversarial examples and streamlining the training procedure, thus making adversarial training more feasible for large-scale applications.
Moreover, adversarial training tends to compromise the network's performance on clean, unperturbed data. This trade-off between accuracy and robustness poses a significant challenge, as it is crucial to maintain high performance on both clean and adversarially perturbed data. To address this issue, researchers have proposed friendly adversarial training[9], which aims to strike a balance between the two. This approach involves carefully designing the training process and selecting adversarial examples that minimally impact the model's accuracy on clean data, thereby achieving a more harmonious trade-off between robustness and performance.
3.1.2 Robust network design
Apart from adversarial training, researchers are actively exploring ways to improve adversarial robustness by designing more resilient network architectures. This approach leverages insights into the network's feature-level vulnerabilities, which are considered the most susceptible parts to adversarial perturbations. Understanding and addressing these weak points can significantly enhance the overall robustness.
One prominent method in this area is feature denoising[65]. Feature denoising techniques aim to cleanse the internal representations of the network from the noise introduced by adversarial examples. By adding denoising modules within the network, these methods can effectively reduce the impact of adversarial perturbations, leading to more robust feature extraction and classification processes. Another approach involves pruning[66], which systematically removes certain neurons or weights from the network that are identified as less critical or highly sensitive to adversarial attacks. By pruning these vulnerable components, the network can potentially become less susceptible to adversarial perturbations. Feature separation and recalibration[67] is another strategy designed to improve network robustness. This technique separates the robust and non-robust feature maps and adjusts the non-robust ones to make them more resistant to adversarial modifications.
3.1.3 Input transformation
Input transformation techniques are a critical defense mechanism against adversarial attacks, involving various preprocessing steps to cleanse the input data of adversarial perturbations before it is processed by the model. These techniques aim to neutralize the malicious alterations introduced by adversarial examples, thus preserving the integrity of the data and ensuring accurate model predictions.
Traditional denoising methods encompass a range of image preprocessing techniques designed to remove noise and restore the original quality of the input data. One such method is total variance minimization[71], which reduces the total variation in an image to smooth out the adversarial noise while preserving essential features. This technique effectively diminishes the impact of small, imperceptible perturbations, making it harder for adversarial examples to deceive the model. Other traditional methods may include median filtering, Gaussian blurring, and bilateral filtering, all aimed at reducing the high-frequency noise introduced by adversarial attacks.
In recent years, a new class of methods known as adversarial purification has gained prominence. These techniques leverage generative models to preprocess and purify the input data. One notable approach in this category involves the use of GANs[12] to generate clean versions of the input data. By training a GAN on the clean data distribution, the generator can learn to produce purified inputs that are free from adversarial perturbations. Other generative models, such as diffusion models[10] and energy-based models[72] are also employed in adversarial purification to reconstruct the input data and eliminate adversarial noise.
While both traditional image denoising and adversarial purification methods have demonstrated significant efficacy in mitigating adversarial attacks, they are not without their drawbacks. One primary concern is that these preprocessing steps can sometimes degrade the performance of the model on clean, unperturbed data. The process of denoising, whether through traditional methods or generative models, may inadvertently remove or alter important features of the input data, leading to a reduction in the model's accuracy on legitimate inputs, which remains a critical challenge of this category of methods.
3.1.4 Certified defenses
Certified defenses aim to provide provable guarantees of robustness against adversarial attacks[68]. Unlike empirical defenses, which rely on observed performance to infer robustness, certified defenses use rigorous mathematical techniques to formally verify that a model's predictions remain stable within a defined perturbation bound. This means that for any input within this bound, the model is guaranteed to produce the same output, thereby ensuring its robustness against a specific range of adversarial perturbations.
One common approach to certified defenses is through Interval Bound Propagation (IBP)[73], which computes bounds on the outputs of a neural network given bounds on its inputs. By propagating these bounds through the network, IBP can certify that the network's output will not change under small input perturbations. Another method involves Lipschitz continuity[69], where the Lipschitz constant of the model is computed to ensure that small changes in the input result in proportionally small changes in the output. Satisfiability Modulo Theories (SMT)[74] solvers and Mixed Integer Linear Programming (MILP)[75] are also used to provide formal guarantees by solving complex optimization problems that model the behavior of neural networks under adversarial conditions.
Despite the promising nature of certified defenses, these methods come with significant computational challenges. The mathematical techniques used to certify robustness often involve solving intricate optimization problems or propagating tight bounds through deep neural networks, which can be computationally expensive and time-consuming. This complexity increases with the size of the model and the dataset, making it difficult to scale certified defenses to large, state-of-the-art models or extensive datasets used in practical applications. Moreover, the bounds within which certified defenses guarantee robustness are typically conservative, meaning they ensure stability only within relatively small perturbation ranges. This limitation can restrict their effectiveness against stronger or more sophisticated adversarial attacks that exceed these bounds.
3.1.5 Ensemble defenses
Ensemble defenses work by training multiple models and combining their predictions to make a final decision based on the consensus or aggregate decision of these models[70]. The fundamental intuition behind this approach is that while an adversarial example might successfully deceive a single model, it is significantly less likely to deceive all models in the ensemble, particularly if these models exhibit diversity in their architectures, training processes, or data subsets. The combination of predictions in an ensemble can also vary, ranging from simple averaging or majority voting to more sophisticated methods like weighted voting or stacking. In weighted voting, for instance, more reliable models (those with higher validation accuracy or robustness) can be given greater influence in the final decision, further enhancing the ensemble's resilience to adversarial attacks.
Despite its advantages, ensemble defenses also face challenges. One significant issue is the computational cost, as training and maintaining multiple models requires considerable resources. Additionally, the increased complexity of managing diverse models can pose practical implementation difficulties. However, the enhanced robustness achieved through ensemble methods often justifies these additional costs, especially in applications where security and reliability are paramount.
3.2 Representative Defense Methods
We list the mainstream adversarial defense methods in Table 3 according to the taxonomy specified above. Overall, adversarial defense is a rapidly evolving field, with ongoing research aimed at developing more robust and efficient techniques to safeguard machine learning models from adversarial attacks. Understanding and combining multiple defense strategies is often necessary to build resilient systems.
Representative adversarial defense methods
4 Beyond Attack and Defense
In the evolving landscape of adversarial examples in computer vision, it is crucial to look beyond the traditional dichotomy of attack and defense. This section delves into the broader implications and deeper understandings of adversarial phenomena. Firstly, we explore the theoretical explanations of adversarial examples, shedding light on the underlying mechanisms that make neural networks vulnerable to these perturbations. By comprehending the theoretical foundations, we can better anticipate and mitigate potential threats. Next, we discuss the trade-off between accuracy and robustness, a critical consideration for deploying robust models in real-world applications. Balancing these often competing objectives is essential for developing systems that are both reliable and performant. Finally, we examine the concept of benign adversarial attacks for the human good, where adversarial techniques are harnessed for beneficial purposes, such as enhancing security and privacy in DNN-based applications. This holistic view aims to provide a comprehensive understanding of the multifaceted nature of adversarial machine learning and its implications for future research and practical deployments.
4.1 Theoretical Explanations of Adversarial Examples
Although adversarial examples are well known in the computer vision field, researchers have not yet reached a consensus about the explanations of their existence. There have been multifaceted theoretical hypotheses over this issue. Different theoretical hypotheses about adversarial examples are shown in Table 4.
Low-probability hypothesis: When adversarial examples were initially defined by Sezgedy et al[3], they made the hypothesis that adversarial examples lie in the low-probability spaces, which are hardly reachable by random sampling around the clean input. As a result, standard training or mere data augmentation strategies provide not guarantee that models can properly tackle adversarial examples.
Linearity hypothesis: Differently, Goodfellow et al[4] assumed that the highly linear behaviors of DNNs are responsible for adversarial examples. Using easy activation functions like ReLUs will prompt the networks to behave more linearly, thus accumulating small perturbations over the network layers and finally causing the incorrect output.
Off-manifold hypothesis: Another hypothesis is that adversarial examples lie off the clean data manifold and obey a different distribution[80]. Inspired by this hypothesis, many defense methods[12,80] involve adversarial detection to distinguish adversarial data from clean data, and then treat them respectively. However, this hypothesis is also questioned by Carlini et al[5] who developed attacks that can easily circumvent adversarial detection.
Manifold geometry hypothesis: Gilmer et al[91] provided another possible explanation about adversarial examples, i.e., the intricate geometric structure of data manifold. By exploring a synthesized dataset, they found that most correctly classified data are close to a misclassified sample, which makes the model rather sensitive to adversarial examples.
To conclude, although some of these hypothetical explanations of adversarial examples are still controversial, they provide us with different research perspectives and are illuminating for us to better understand the nature of DNNs.
Theoretical hypotheses about adversarial examples
4.2 Trade-Off Between Accuracy and Robustness
The trade-off between accuracy and robustness in adversarial defense is a well-recognized challenge in the field of adversarial examples in computer vision[92]. This trade-off arises because methods that enhance a model's robustness to adversarial attacks often come at the expense of the model's accuracy on clean, unperturbed data, regardless of the defense method. This phenomenon might be explained from the following perspectives:
Generalization trade-off: Robust models may prioritize learning features that help in distinguishing between adversarial and non-adversarial inputs. This focus can sometimes obscure the learning of features that are essential for accurate predictions on clean data, thereby reducing the overall accuracy.
Robust loss functions: Incorporating robustness into the loss function, such as through robust optimization techniques, can alter the optimization landscape. While these robust loss functions are effective at mitigating the impact of adversarial attacks, they might not be as effective in optimizing for accuracy on clean data. The trade-off is often seen as a shift from minimizing error on clean data to maintaining performance under adversarial conditions.
Model capacity: Enhancing robustness typically requires increasing the model's capacity, which can lead to overfitting if not managed correctly. Overfitting to adversarial examples during training can degrade performance on clean examples. This trade-off highlights the difficulty in balancing the model's capacity to handle both adversarial and clean inputs effectively.
4.3 Benign Adversarial Attacks for the Human Good
Adversarial attacks, while often perceived negatively due to their potential to exploit vulnerabilities in DNN models, can also be harnessed for beneficial purposes. By understanding and leveraging the mechanisms behind adversarial examples, researchers can develop innovative solutions that serve the human good. In the following examples, we illustrate how adversarial examples can be used constructively.
One significant application is in the realm of privacy protection. Hu et al[55] proposed a method to utilize adversarial attacks to safeguard facial privacy. They developed a make-up transfer attack that alters facial images in such a way that unauthorized facial recognition systems on social media are unable to identify the individuals. This method not only preserves privacy but also allows individuals to maintain their online presence without the fear of unauthorized surveillance or data misuse.
Another compelling application involves the prevention of malicious Artificial Intelligence Generated Content (AIGC). Salman et al[93] introduced a technique where adversarial perturbations are injected into images uploaded on the internet, acting as an "immunization" against malicious AI editing. When diffusion-based generative models[94] attempt to edit these immunized images, the result is unnatural and obviously tampered with, thereby protecting the original content from unauthorized manipulation. This approach highlights the potential of using adversarial techniques to counteract the misuse of advanced AI tools and ensure the integrity of online content.
These examples demonstrate that adversarial samples, often seen as a threat, can be repurposed to serve protective and ethical functions in an era of rapid AI development. By transforming the way we approach adversarial attacks, we can develop robust systems that not only defend against malicious activities but also enhance privacy and security in various digital environments.
5 Discussion
Despite significant advancements, the continuous evolution of adversarial techniques poses ongoing challenges that necessitate further research and innovation. This chapter aims to provide a comprehensive discussion on the current state of adversarial attack and defense, highlighting key open problems and proposing future directions to address these challenges.
5.1 Open Problems
Scalability and efficiency of defenses: One significant challenge in the field of adversarial attack and defense is the scalability and efficiency of defense mechanisms. Many current methods, such as adversarial training[6,11], require substantial computational resources and long training times, making them impractical for large-scale datasets and complex models[95]. This limitation hinders their deployment in real-world applications, especially in environments where computational power and time are critical factors. Additionally, the high computational cost can limit the ability of researchers to experiment with and improve these methods, slowing down the progress in developing more robust defenses.
Generalization of defenses across domains: Another major issue is the lack of generalization of defense mechanisms across different domains. Most adversarial defenses are designed and optimized for specific tasks, such as image classification, and do not perform well when applied to other domains like Natural Language Processing (NLP)[96-98] or Reinforcement Learning (RL)[99-101]. This task-specific nature limits the applicability and effectiveness of these defenses in broader contexts, leaving many areas vulnerable to adversarial attacks. The diversity of data types and model architectures across domains further complicates the development of universally robust defenses.
Understanding and mitigating transferability of adversarial examples: The transferability of adversarial examples, where an attack crafted for one model can also deceive other models, presents a persistent challenge[102,103]. This phenomenon makes it difficult to protect against adversarial attacks in environments with diverse model deployments. Transferability complicates the defense landscape, as it suggests that improving the robustness of individual models might not be sufficient. The underlying mechanisms driving transferability are not yet fully understood, making it a critical area of concern for researchers aiming to develop comprehensive defense strategies.
5.2 Future Directions
Existing adversarial defense strategies have the following main problems: scalability and efficiency of defenses, Generalization of defenses across domains and understanding and mitigating transferability of adversarial examples. Aware of the open problems discussed above, future research in this domain is likely to prioritize several key areas to further enhance the robustness and security of these systems.
First, to address the scalability and efficiency issues of current defense mechanisms, future research should focus on developing methods that are computationally efficient and scalable. Techniques like fast adversarial training, which aims to reduce the computational overhead without compromising robustness, are promising areas of exploration. Additionally, leveraging distributed computing and parallel processing can help in scaling defense mechanisms to handle larger datasets and more complex models efficiently.
Second, to address the lack of cross-domain generality of current defense mechanisms, there is a pressing need for generalized defense mechanisms that can be applied across various domains. Future research can develop general defense frameworks that are not limited to specific tasks. Cross-domain robustness studies, which investigate the applicability of defenses across different types of data and models, can provide insights into creating versatile defense strategies. Additionally, developing benchmarks and evaluation metrics for cross-domain robustness will help in assessing and improving these generalized defenses.
Finally, in response to the current pain point of the high transferability of adversarial examples, future research should aim to understand the underlying factors that contribute to the transferability of adversarial examples. Investigating the properties of adversarial examples and model architectures that influence transferability can provide valuable insights. Based on these insights, researchers can develop mitigation strategies that reduce the effectiveness of transferable attacks. Collaborative efforts to share findings and develop standardized approaches to mitigate transferability will be crucial in advancing this area.
6 Conclusion
Driven by the discovery of adversarial examples in computer vision, adversarial attacks and defenses have garnered significant attention over the past decades. This surge in interest has led to a plethora of innovative techniques aimed at both attacking and defending DNNs. In conclusion, while significant progress has been made in understanding and mitigating adversarial attacks, the field remains highly dynamic and challenging. Ongoing research must continue to innovate and adapt to ensure the development of robust, secure DNN models capable of withstanding adversarial threats across diverse applications.
References
- He K M, Zhang X Y, Ren S Q, et al .Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2016: 770-778. [Google Scholar]
- Vaswani A, Shazeer N, Parmar N, et al .Attention is all you need[C]//2017 Conference on Neural Information Processing Systems (NeurIPS). Long Beach: Neural Information Processing Systems Foundation, 2017: 5998-6008. [Google Scholar]
- Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[EB/OL]. [2014-02-19]. https://arxiv.org/abs/1312.6199. [Google Scholar]
- Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[EB/OL]. [2015-03-20]. https://arxiv.org/abs/1412.6572. [Google Scholar]
- Carlini N, Wagner D. Towards evaluating the robustness of neural networks[C]//2017 IEEE Symposium on Security and Privacy (SP). New York: IEEE, 2017: 39-57. [Google Scholar]
- Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[EB/OL]. [2019-09-04]. https://arxiv.org/abs/1706.06083. [Google Scholar]
- Kurakin A, Goodfellow I J, Bengio S. Adversarial examples in the physical world[C]//5th International Conference on Learning Representations. Chapman and Hall: CRC, 2017: 99-112. [Google Scholar]
- Zhang H Y, Yu Y D, Jiao J T, et al .Theoretically principled trade-off between robustness and accuracy[C]//2019 Proceedings of the 36th International Conference on Machine Learning (ICML). Long Beach: PMLR, 2019: 7472-7482. [Google Scholar]
- Zhang J F, Xu X L, Han B, et al .Attacks which do not kill training make adversarial learning stronger[C]//2020 Proceedings of the 37th International Conference on Machine Learning (ICML). Virtual Event: PMLR, 2020: 11278-11287. [Google Scholar]
- Nie W, Guo B, Huang Y, et al .Diffusion models for adversarial purification[C]//2022 Proceedings of the International Conference on Machine Learning (ICML). Baltimore: PMLR, 2022: 16805-16827. [Google Scholar]
- Jia X J, Zhang Y, Wu B Y, et al .LAS-AT: Adversarial training with learnable attack strategy[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans: PMLR, 2022: 13388-13398. [Google Scholar]
- Samangouei P, Kabkab M, Chellappa R. Defense-GAN: Protecting classifiers against adversarial attacks using generative models[EB/OL]. [2018-05-18]. https://arxiv.org/abs/1805.06605. [Google Scholar]
- Song Y, Kim T, Nowozin S, et al. PixelDefend: Leveraging generative models to understand and defend against adversarial examples[EB/OL]. [2018-05-21]. http://arxiv.org/abs/1710.10766. [Google Scholar]
- Serban A, Poll E, Visser J. Adversarial examples on object recognition[J]. ACM Computing Surveys, 2020, 53(3): 1-38. [Google Scholar]
- Machado G R, Silva E, Goldschmidt R R. Adversarial machine learning in image classification: A survey toward the defender's perspective[J]. ACM Computing Surveys, 2021, 55(1): 1-38. [Google Scholar]
- Long T, Gao Q, Xu L L, et al. A survey on adversarial attacks in computer vision: Taxonomy, visualization and future directions[J]. Computers & Security, 2022, 121: 102847. [CrossRef] [Google Scholar]
- Wang J, Wang C Y, Lin Q Z, et al. Adversarial attacks and defenses in deep learning for image recognition: A survey[J]. Neurocomputing, 2022, 514: 162-181. [CrossRef] [Google Scholar]
- Li Y J, Xie B, Guo S T, et al. A survey of robustness and safety of 2D and 3D deep learning models against adversarial attacks[J]. ACM Computing Surveys, 2024, 56(6): 1-37. [CrossRef] [Google Scholar]
- Costa J C, Roxo T, Proença H, et al. How deep learning sees the world: A survey on adversarial attacks & defenses[J]. IEEE Access, 2024, 12: 61113-61136. [NASA ADS] [CrossRef] [Google Scholar]
- Akhtar N, Mian A. Threat of adversarial attacks on deep learning in computer vision: A survey[J]. IEEE Access, 2018, 6: 14410-14430. [CrossRef] [Google Scholar]
- Metzen J H, Kumar M C, Brox T, et al .Universal adversarial perturbations against semantic image segmentation[C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2017: 2774-2783. [Google Scholar]
- Xie C H, Wang J Y, Zhang Z S, et al .Adversarial examples for semantic segmentation and object detection[C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE, 2017: 1378-1387. [Google Scholar]
- Pony R, Naeh I, Mannor S. Over-the-air adversarial flickering attacks against video recognition networks[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2021: 515-524. [Google Scholar]
- Eykholt K, Evtimov I, Fernandes E, et al .Robust physical-world attacks on deep learning visual classification[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 1625-1634. [Google Scholar]
- Finlayson S G, Bowers J D, Ito J, et al. Adversarial attacks on medical machine learning[J]. Science, 2019, 363(6433): 1287-1289. [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Song Y, Kim T, Nowozin S, et al. PixelDefend: Leveraging generative models to understand and defend against adversarial examples[EB/OL]. [2018-05-21]. https://arxiv.org/abs/1710.10766. [Google Scholar]
- Andriushchenko M, Croce F, Flammarion N, et al .Square attack: A query-efficient black-box adversarial attack via random search[C]//Lecture Notes in Computer Science. Cham: Springer-Verlag, 2020: 484-501. [Google Scholar]
- Zhao Z Y, Liu Z R, Larson M. Towards large yet imperceptible adversarial image perturbations with perceptual color distance[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 1036-1045. [Google Scholar]
- Xiao C W, Zhu J Y, L B, et al. Spatially transformed adversarial examples[EB/OL]. [2018-01-09]. https://arxiv.org/abs/1801.02612. [Google Scholar]
- Brown T B, Mané D, Roy A, et al. Adversarial patch[EB/OL]. [2018-05-17]. https://arxiv.org/abs/1712.09665. [Google Scholar]
- Li J, Schmidt F R, Kolter J Z. Adversarial camera stickers: A physical camera-based attack on deep learning systems[C]//2019 Proceedings of the 36th International Conference on Machine Learning (ICML). Long Beach: PMLR, 2019: 3896-3904. [Google Scholar]
- Goodfellow I J, Pouget-Abadie J, Mirza M, et al .Generative adversarial nets[C]//2014 Proceedings of the Advances in Neural Information Processing Systems (NeurIPS). Montreal: NeurIPS, 2014: 2672-2680. [Google Scholar]
- He Z W, Wang W, Dong J, et al. Transferable sparse adversarial attack[EB/OL]. [2021-05-31]. https://arxiv.org/abs/2105.14727. [Google Scholar]
- Papernot N, McDaniel P, Jha S, et al .The limitations of deep learning in adversarial settings[C]//2016 IEEE European Symposium on Security and Privacy (EuroS&P). New York: IEEE, 2016: 372-387. [Google Scholar]
- Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Zhang R, Isola P, Efros A A, et al .The unreasonable effectiveness of deep features as a perceptual metric[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). New York: IEEE, 2018: 586-595. [Google Scholar]
- Song Y, Shu R, Kushman N, et al .Constructing unrestricted adversarial examples with generative models[C]//2018 Proceedings of the Advances in Neural Information Processing Systems (NeurIPS). Montreal: NeurIPS, 2018: 8322-8333. [Google Scholar]
- Moosavi-Dezfooli S M, Fawzi A, Frossard P. DeepFool: A simple and accurate method to fool deep neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2016: 2574-2582. [Google Scholar]
- Moosavi-Dezfooli S M, Fawzi A, Fawzi O, et al .Universal adversarial perturbations[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2017: 86-94. [Google Scholar]
- Brendel W, Rauber J, Bethge M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models[EB/OL]. [2018-02-16]. https://arxiv.org/abs/1712.04248. [Google Scholar]
- Modas A, Moosavi-Dezfooli S M, Frossard P. SparseFool: A few pixels make a big difference[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 9079-9088. [Google Scholar]
- Xie C H, Zhang Z S, Zhou Y Y, et al .Improving transferability of adversarial examples with input diversity[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 2725-2734. [Google Scholar]
- Dong Y P, Pang T Y, Su H, et al .Evading defenses to transferable adversarial examples by translation-invariant attacks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 4307-4316. [Google Scholar]
- Lin J D, Song C B, He K, et al. Nesterov accelerated gradient and scale invariance for adversarial attacks[EB/OL]. [2020-02-03]. https://arxiv.org/abs/1908.06281v5. [Google Scholar]
- Chen X S, Yan X Y, Zheng F, et al .One-shot adversarial attacks on visual tracking with dual attention[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 10173-10182. [Google Scholar]
- Croce F, Hein M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks[C]//2020 Proceedings of the 37th International Conference on Machine Learning (ICML). New York: PMLR, 2020: 2206-2216. [Google Scholar]
- Qiu H N, Xiao C W, Yang L, et al .SemanticAdv: Generating adversarial examples via attribute-conditioned image editing[C]//European Conference on Computer Vision. Cham: Springer-Verlag, 2020: 19-37. [Google Scholar]
- Chen J H, Gu Q Q. RayS: A ray searching method for hard-label adversarial attack[C]//2020 Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2020: 1739-1747. [Google Scholar]
- Mahmood K, Nguyen P H, Nguyen L M, et al. Buzz: Buffer zones for defending adversarial examples in image classification[EB/OL]. [2020-06-16]. https://arxiv.org/abs/1910.02785. [Google Scholar]
- Chen S Z, He Z B, Sun C J, et al. Universal adversarial attack on attention and the resulting dataset DAmageNet[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 2188-2197. [PubMed] [Google Scholar]
- Wu W B, Su Y X, Chen X X, et al .Boosting the transferability of adversarial samples via attention[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 1158-1167. [Google Scholar]
- Mahmood K, Mahmood R, van Dijk M. On the robustness of vision transformers to adversarial examples[C]//2021 IEEE/CVF International Conference on Computer Vision (ICCV). New York: IEEE, 2021: 7818-7827. [Google Scholar]
- Shahin Shamsabadi A, Oh C, Cavallaro A. Semantically adversarial learnable filters[J]. IEEE Transactions on Image Processing, 2021, 30: 8075-8087. [NASA ADS] [CrossRef] [MathSciNet] [PubMed] [Google Scholar]
- Zhao Z Y, Liu Z R, Larson M A. On success and simplicity: A second look at transferable targeted attacks[C]//2021 Advances in Neural Information Processing Systems (NeurIPS). Virtual: NeurIPS, 2021: 6115-6128. [Google Scholar]
- Hu S S, Liu X G, Zhang Y C, et al .Protecting facial privacy: Generating adversarial identity masks via style-robust makeup transfer[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2022: 14994-15003. [Google Scholar]
- Zhang J P, Wu W B, Huang J T, et al .Improving adversarial transferability via neuron attribution-based attacks[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2022: 14973-14982. [Google Scholar]
- Bai Y, Wang Y S, Zeng Y Y, et al. Query efficient black-box adversarial attack on deep neural networks[J]. Pattern Recognition, 2023, 133: 109037. [CrossRef] [Google Scholar]
- Chen Z Y, Li B, Wu S, et al. Content-based unrestricted adversarial attack[EB/OL]. [2023-11-29]. https://arxiv.org/abs/2305.10665. [Google Scholar]
- Duan M X, Qin Y C, Deng J Y, et al. Dual attention adversarial attacks with limited perturbations[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 99: 1-15. [Google Scholar]
- Wang X S, He K. Enhancing the transferability of adversarial attacks through variance tuning[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2021: 1924-1933. [Google Scholar]
- Jain S, Dutta T. Towards understanding and improving adversarial robustness of vision transformers[C]//2024 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2024: 24736-24745. [Google Scholar]
- Jain S, Dutta T. Towards understanding and improving adversarial robustness of vision transformers[C]//2024 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2024: 24736-24745. [Google Scholar]
- Wang Y S, Zou D F, Yi J F, et al .Improving adversarial robustness requires revisiting misclassified examples[C]//2020 8th International Conference on Learning Representations (ICLR). Addis Ababa: OpenReview.net, 2020. [Google Scholar]
- Wong E, Rice L, Kolter J Z. Fast is better than free: Revisiting adversarial training[EB/OL]. [2020-01-12]. https://arxiv.org/abs/2001.03994v1. [Google Scholar]
- Xie C H, Wu Y X, van der Maaten L, et al .Feature denoising for improving adversarial robustness[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 501-509. [Google Scholar]
- Madaan D, Shin J, Hwang S J. Adversarial neural pruning with latent vulnerability suppression[C]//2020 Proceedings of the 37th International Conference on Machine Learning (ICML). New York: PMLR, 2020: 6575-6585. [Google Scholar]
- Kim W J, Cho Y, Jung J, et al .Feature separation and recalibration for adversarial robustness[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2023: 8183-8192. [Google Scholar]
- Huang X W, Kwiatkowska M, Wang S, et al .Safety verification of deep neural networks[C]//2017 Proceedings of the 29th International Conference on Computer Aided Verification (CAV). Heidelberg: Springer-Verlag, 2017: 3-29. [Google Scholar]
- Gowal S, Dvijotham K, Stanforth R, et al. On the effectiveness of interval bound propagation for training verifiably robust models[EB/OL]. [2019-08-29]. http://arxiv.org/abs/1810.12715. [Google Scholar]
- Tramèr F, Kurakin A, Papernot N, et al. Ensemble adversarial training: Attacks and defenses[EB/OL]. [2020-04-26].https://arxiv.org/abs/1705.07204v5. [Google Scholar]
- Guo C, Rana M, Cissé M, et al. Countering adversarial images using input transformations[EB/OL]. [2018-01-25]. https://arxiv.org/abs/1711.00117v2. [Google Scholar]
- Hill M, Mitchell J C, Zhu S C. Stochastic security: Adversarial defense using long-run dynamics of energy-based models[EB/OL]. [2021-03-18]. https://arxiv.org/abs/2005.13525. [Google Scholar]
- Gowal S, Dvijotham K, Stanforth R, et al. On the effectiveness of interval bound propagation for training verifiably robust models[EB/OL]. [2019-08-29]. http://arxiv.org/abs/1810.12715. [Google Scholar]
- Ehlers R. Formal verification of piece-wise linear feed-forward neural networks[C]//2017 Proceedings of the 15th International Symposium on Automated Technology for Verification and Analysis (ATVA). Heidelberg: Springer-Verlag, 2017: 269-286. [Google Scholar]
- Tjeng V, Xiao K Y, Tedrake R. Evaluating robustness of neural networks with mixed integer programming[EB/OL]. [2019-02-18]. https://arxiv.org/abs/1711.07356v2. [Google Scholar]
- Qin Y, Zhang C Y, Chen T, et al. Understanding and improving robustness of vision transformers through patch-based negative augmentation[J]. Advances in Neural Information Processing Systems, 2022, 35: 16276-16289. [Google Scholar]
- Dong J H, Moosavi-Dezfooli S M, Lai J H, et al .The enemy of my enemy is my friend: Exploring inverse adversaries for improving adversarial training[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2023: 24678-24687. [Google Scholar]
- Jia X J, Li J S, Gu J D, et al. Fast propagation is better: Accelerating single-step adversarial training via sampling subnetworks[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 4547-4559. [CrossRef] [Google Scholar]
- Ali K, Bhatti M S, Saeed A, et al. Adversarial robustness of vision transformers versus convolutional neural networks[J]. IEEE Access, 2024, 12: 105281-105293. [CrossRef] [Google Scholar]
- Meng D Y, Chen H. Magnet: A two-pronged defense against adversarial examples[C]//Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017: 135-147. [Google Scholar]
- Jia X J, Wei X X, Cao X C, et al .ComDefend: An efficient image compression model to defend adversarial examples[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 6077-6085. [Google Scholar]
- Zhou J L, Liang C, Chen J. Manifold projection for adversarial defense on face recognition[C]//Computer Vision--ECCV 2020: 16th European Conference. Berlin: Springer-Verlag, 2020: 288-305. [Google Scholar]
- Ho C H, Vasconcelos N. DISCO: Adversarial defense with local implicit functions[J]. Advances in Neural Information Processing Systems, 2022, 35: 23818-23837. [Google Scholar]
- Wong E, Kolter J Z. Provable defenses against adversarial examples via the convex outer adversarial polytope[C]//2018 Proceedings of the 35th International Conference on Machine Learning (ICML). New York: PMLR, 2018, 80: 5283-5292. [Google Scholar]
- Chiang P Y, Ni R K, Abdelkader A, et al. Certified defenses for adversarial patches[EB/OL]. [2020-09-25]. https://arxiv.org/abs/2003.06693. [Google Scholar]
- Chen Z Y, Li B, Xu J H, et al .Towards practical certifiable patch defense with vision transformer[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2022: 15127-15137. [Google Scholar]
- Pang T Y, Xu K, Du C, et al .Improving adversarial robustness via promoting ensemble diversity[C]//2019 Proceedings of the 36th International Conference on Machine Learning (ICML). New York: PMLR, 2019, 97: 4970-4979. [Google Scholar]
- Bui A T, Le T, Zhao H, et al. Improving ensemble robustness by collaboratively promoting and demoting adversarial robustness[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(8): 6831-6839. [CrossRef] [Google Scholar]
- Wang H J, Wang Y S. Self-ensemble adversarial training for improved robustness[EB/OL]. [2022-05-03]. https://arxiv.org/abs/2203.09678. [Google Scholar]
- Deng Y A, Mu T T. Understanding and improving ensemble adversarial defense[EB/OL].[2023-11-02]. https://arxiv.org/abs/2310.18477. [Google Scholar]
- Gilmer J, Metz L, Faghri F, et al. Adversarial spheres[EB/OL]. [2018-09-10]. https://arxiv.org/abs/1801.02774. [Google Scholar]
- Tsipras D, Santurkar S, Engstrom L, et al. Robustness may be at odds with accuracy[EB/OL]. [2019-09-09]. https://arxiv.org/abs/1805.12152. [Google Scholar]
- Salman H, Khaddaj A, Leclerc G, et al. Raising the cost of malicious AI-powered image editing[EB/OL]. [2023-02-13]. https://arxiv.org/abs/2302.06588. [Google Scholar]
- Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[EB/OL]. [2020-12-16]. https://arxiv.org/abs/2006.11239. [Google Scholar]
- Cao Q, Shen L, Xie W D, et al .VGGFace2: A dataset for recognising faces across pose and age[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). New York: IEEE, 2018: 67-74. [Google Scholar]
- Gao J, Lanchantin J, Soffa M L, et al .Black-box generation of adversarial text sequences to evade deep learning classifiers[C]//2018 IEEE Security and Privacy Workshops (SPW). New York: IEEE, 2018: 50-56. [Google Scholar]
- Ren S H, Deng Y H, He K, et al .Generating natural language adversarial examples through probability weighted word saliency[C]//2019 Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2019: 1085-1097. [Google Scholar]
- Jin D, Jin Z J, Zhou J T, et al. Is BERT really robust? A strong baseline for natural language attack on text classification and entailment[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 8018-8025. [CrossRef] [Google Scholar]
- Lin Y C, Hong Z W, Liao Y H, et al .Tactics of adversarial attack on deep reinforcement learning agents[C]//2017 Proceedings of the 26th International Joint Conference on Artificial Intelligence. Berkeley: International Joint Conferences on Artificial Intelligence Organization, 2017: 3756-3762. [Google Scholar]
- Liu F, Shroff N B. Data poisoning attacks on stochastic bandits[C]//2019 Proceedings of the 36th International Conference on Machine Learning (ICML). New York: PMLR, 2019: 4042-4050. [Google Scholar]
- Gleave A, Dennis M, Wild C, et al .Adversarial policies: Attacking deep reinforcement learning[C]//2020 Proceedings of the 8th International Conference on Learning Representations (ICLR). Addis Ababa: OpenReview.net, 2020. [Google Scholar]
- Papernot N, McDaniel P, Goodfellow I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples[EB/OL]. [2016-05-24]. https://arxiv.org/abs/1605.07277. [Google Scholar]
- Chen Y B, Liu W W. A theory of transfer-based black-box attacks: Explanation and implications[C]//NIPS'23: 37th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc, 2024: 13887-13907. [Google Scholar]
All Tables
All Figures
|
Fig. 1 An example showing the implementation of adversarial attacks |
| In the text | |
|
Fig. 2 The taxonomy of adversarial attacks |
| In the text | |
|
Fig. 3 A schematic diagram of untargeted attacks (a) and targeted attacks (b) in the 2D feature space
|
| In the text | |
|
Fig. 4 A schematic figure of attacks with different adversarial knowledge |
| In the text | |
|
Fig. 5 Different perturbation structures of adversarial attacks |
| In the text | |
|
Fig. 6 Taxonomy of adversarial defenses |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.