| Issue |
Wuhan Univ. J. Nat. Sci.
Volume 31, Number 1, February 2026
|
|
|---|---|---|
| Page(s) | 69 - 78 | |
| DOI | https://doi.org/10.1051/wujns/2026311069 | |
| Published online | 06 March 2026 | |
Computer Applications and Software
CLC number: TP301
A Real-Time Task Scheduling Algorithm Based on Bilateral Matching Games in a Distributed Computing Environment
分散计算环境下基于双边匹配博弈的实时任务调度算法
1
School of Intelligent Manufacturing, Huanghuai University, Zhumadian 463000, Henan, China
(黄淮学院 智能制造学院,河南 驻马店 463000)
2
School of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, Jiangsu, China
(南京邮电大学 计算机科学学院,江苏 南京 210023)
3
Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China
(清华大学 计算机科学与技术系,北京 100084)
† Corresponding author. E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
4
September
2025
Abstract
In the era of the Internet of Things, distributed computing alleviates the problem of insufficient terminal computing power by integrating idle resources of heterogeneous devices. However, the imbalance between task execution delay and node energy consumption, and the scheduling and adaptation challenges brought about by device heterogeneity, urgently need to be addressed. To tackle this problem, this paper constructs a multi-objective real-time task scheduling model that considers task real-time performance, execution delay, system energy consumption, and node interests. The model aims to minimize the delay upper bound and total energy consumption while maximizing system satisfaction. A real-time task scheduling algorithm based on bilateral matching game is proposed. By designing a bidirectional preference mechanism between tasks and computing nodes, combined with a multi-round stable matching strategy, accurate matching between tasks and nodes is achieved. Simulation results show that compared with the baseline scheme, the proposed algorithm significantly reduces the total execution cost, effectively balances the task execution delay and the energy consumption of compute nodes, and takes into account the interests of each network compute node.
摘要
在万物互联时代,分散计算通过整合异构设备空闲资源缓解了终端计算能力不足的问题,但任务执行延迟与节点能耗的博弈不平衡、设备异构性带来的调度适配难题亟待解决。针对该问题,本文构建了兼顾任务实时性、执行延迟、系统能耗与节点利益的多目标实时任务调度模型,以最小化延迟上限与总能耗、最大化系统满意度为优化目标,提出了基于双边匹配博弈的实时任务调度算法。通过设计任务-计算节点双向偏好机制,结合多轮次稳定匹配策略,实现任务与节点的精准适配;同时引入次级判断规则解决偏好冲突,保障调度公平性与效率。仿真实验表明,与基线相比,该算法显著降低了总执行成本,有效平衡了任务执行延迟和计算节点的能耗,并兼顾了网络中每个计算节点的利益。
Key words: dispersed computing / real-time task / task scheduling / bilateral matching game
关键字 : 分散计算 / 实时任务 / 任务调度 / 双边匹配博弈
Cite this article:LI Shuo, FANG Zuying, ZHOU Guoqiang, et al. A Real-Time Task Scheduling Algorithm Based on Bilateral Matching Games in a Distributed Computing Environment[J]. Wuhan Univ J of Nat Sci, 2026, 31(1): 69-78.
Biography: LI Shuo, female, Master candidate, research direction: computer applications, knowledge graph. E-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Foundation item: Supported by the National Program on Key Basic Research Project (2020YFA0713600) and the National Natural Science Foundation of China (62272214)
© Wuhan University 2026
 This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
DOI https://doi.org/10.1051/wujns/2026311069
0 Introduction
With the advent of the Internet of Everything (IoE) era, a dramatic increase in the number of Internet of Things (IoT) devices has been witnessed. These devices generally operate independently and exhibit a wide geographical distribution. Such a dispersed nature gives rise to a significant challenge, wherein the potential computational capability of numerous IoT devices is not fully utilized. To address this challenge, dispersed computing has emerged as a promising paradigm. Dispersed Computing aims to construct a decentralized, distributed, and resource-heterogeneous network entity by leveraging the computational resources of ubiquitous smart devices, such as smartphones, tablets, and IoT terminals[1-2]. Its objective is to enhance the efficiency, security, and reliability of distributed systems without increasing centralized control, thereby compensating for the high latency and cost deficiencies of the cloud computing paradigm, and addressing the issues of limited coverage areas of edge nodes and the inability of terminal nodes to collaborate directly in mobile edge computing.
While dispersed computing improves system throughput by scheduling compute-intensive tasks to nearby available networked computation nodes for execution, performing rational scheduling for real-time tasks among these dispersed and heterogeneous devices poses significant challenges. First, the computational resources of networked computation nodes are limited, and they should be entitled to accept or reject task execution requests to guarantee their own operational stability. Second, significant differences exist among tasks in terms of data volume, computational workload, and completion deadlines; thus, task scheduling and resource allocation should be compatible with the interests of the tasks. Finally, while ensuring the real-time execution of tasks, the energy consumption of each networked computing node must also be considered, necessitating a balance between task execution latency and the energy consumption of these nodes.
To address the aforementioned challenges and resolve the imbalance in the trade-off between task execution latency and energy consumption in dispersed computing environments, this paper constructs a real-time task scheduling model for such environments. This model accommodates the interests of both tasks and networked computation nodes, aiming to minimize task execution latency and system energy consumption while maximizing overall system satisfaction, all under the constraint of ensuring real-time task execution. Furthermore, a real-time task scheduling algorithm based on a two-sided matching game is designed to obtain the scheduling strategy. This approach allows tasks and networked computation nodes to make selections proactively based on their preference rules, thereby achieving an optimal balance between task execution latency and the energy consumption of the nodes. Finally, through comparative analysis in simulation experiments from various perspectives, the effectiveness and superiority of the proposed algorithm are verified in terms of task execution latency, system energy consumption, satisfaction, and throughput.
The main contributions of this paper are summarized as follows:
1) A real-time task scheduling framework for dispersed computing environments is constructed, which is tailored to the characteristics of dispersed computing scenarios. This framework accommodates the interests of both tasks and networked computation nodes, with the optimization objective of minimizing task execution latency and system energy consumption while maximizing overall system satisfaction.
2) A real-time task scheduling algorithm based on a two-sided matching game is proposed and designed. Through the rational design of preference rules, a balance between task latency and the energy consumption of networked computation nodes is achieved, enabling an effective matching between tasks and networked computation nodes.
In this paper, extensive simulation experiments are designed to evaluate the performance of the proposed algorithm and the advantages of dispersed computing. The simulation results demonstrate that the algorithm proposed in this paper effectively balances the execution latency of tasks with the energy consumption of computing nodes, while accommodating the interests of all networked computation nodes.
1 Related Work
In the research area of dispersed computing, progress has been made on issues such as user anonymity processing[3], fine-grained data packet monitoring in networks[4], application-level congestion control[5], and privacy and security protection[6]. In terms of architectural design, Ghosh et al[7] proposed a container orchestration architecture for dispersed computing, while Yang et al[8] introduced a functional architecture for dispersed computing along with three core technologies.
The resource optimization approach of mobile edge computing provides an early technical reference for distributed computing. This type of research focuses on the joint optimization of task offloading and resource allocation. The core goal is to balance latency and energy consumption in a static network environment. An et al[9] decomposed the task offloading strategy, communication resource allocation and computing resource scheduling into multi-objective optimization problems for IoT edge scenarios. They solved the problem by using the golden search method and achieved the minimization of energy consumption under latency constraints. Li et al[10] introduced potential game theory and designed a distributed task offloading mechanism. They used the game equilibrium characteristics to ensure the stability of energy consumption reduction. Song et al[11] further proposed an offloading algorithm based on network topology for multi-service scenarios. They reduced the overall system cost by refining the task type and node matching rules. However, such methods are essentially an extension of the static architecture of MEC. Their optimization premise is that the network topology and node resource status are relatively fixed. They do not consider the characteristics of dynamic node addition/exit and intermittent link interruption in distributed computing. For example, when faced with sudden traffic spikes or node failures, the existing offloading strategy cannot quickly adjust the task allocation logic, resulting in the failure of global real-time collaboration among multiple tasks, making it difficult to directly migrate to dynamic scenarios of distributed computing.
To adapt to the dynamic changes in the network environment, some studies have turned to reinforcement learning technology to achieve real-time optimization of scheduling strategies through the interaction between agents and the environment. Kuang et al[12] proposed an integrated framework based on deep reinforcement learning, which models task offloading, scheduling decisions and resource allocation as Markov decision processes and uses deep neural networks to fit the optimal strategy, effectively reducing system latency and energy consumption in multi-user scenarios. Sacco et al[13] further constructed a multi-agent reinforcement learning architecture, allowing each node to participate in decision-making as an independent agent, which improved the distributed collaboration capability of task scheduling in unmanned aerial vehicle (UAV) networks. Seid et al[14] extended this idea to multi-UAV IoT edge networks, and solved task offloading conflicts between heterogeneous nodes through multi-agent deep reinforcement learning. Although such methods are superior to traditional strategies in terms of dynamic adaptation, their limitations are still quite prominent: First, they rely on fixed infrastructure. When nodes in distributed computing are randomly distributed personal devices, infrastructure dependence leads to a significant decrease in the scalability of the algorithm. Second, they ignore the core advantage of mining the value of idle resources in distributed computing. That is, existing models mostly assume that node resources are pre-allocated dedicated resources, do not consider the dynamic utilization of idle computing power of neighboring nodes, and do not quantify the utility feedback of node contribution computing power, resulting in low resource utilization.
In response to the adaptability defects of the first two types of methods, recent research has begun to focus on the scenario characteristics of distributed computing and design dedicated scheduling frameworks. The core objective is to solve the problems of throughput optimization and extreme scenario adaptation in dynamic heterogeneous networks. Niu et al[15] constructed a distributed computing network architecture for disaster emergency scenarios and used Lyapunov optimization technology to handle the dynamics of task queues. While ensuring queue stability, they reduced system energy consumption and provided a feasible solution for distributed scheduling in extreme environments. Poylisher et al[16] designed an anti-interference scheduling framework for tactical edge networks and used fault tolerance mechanisms to deal with challenges such as node loss and bandwidth limitation, ensuring the continuous execution of tactical tasks. Yang et al[17] and Hu et al[18] made breakthroughs from the perspective of task models. The former used virtual queuing networks and maximum weight scheduling to achieve the optimal throughput of task chains and directed acyclic graph (DAG) models. The latter designed a throughput optimization scheduler for continuous and stable data input scenarios, which can still maintain efficient task processing when link bandwidth fluctuates and computational load is high. While such frameworks align with the distributed and dynamic requirements of distributed computing, significant research gaps remain. Existing work primarily focuses on increasing system throughput and shortening task execution time, with attention to node energy consumption limited to basic constraints such as not exceeding thresholds. A triangular balance mechanism between latency, energy consumption, and real-time performance has not been established. However, in distributed computing, many nodes are battery-powered mobile devices with limited energy resources. Simply pursuing throughput or low latency can lead to node energy overload, ultimately reducing long-term system stability—this core contradiction is a critical issue that current research has yet to address.
In summary, while existing distributed computing scheduling research has made progress in dynamic adaptation and scenario-specificity, it still falls short in multi-objective collaborative optimization and the utilization of idle resources. This paper addresses this gap by constructing a scheduling model that balances task real-time performance, node energy consumption, and system satisfaction. Furthermore, it aligns the interests of tasks and nodes through a two-sided matching game, thus overcoming the limitations of existing research.
2 A Real-Time Task Scheduling Framework
Based on the presence or absence of task execution requests, networked computation nodes are categorized into two types: those with task execution demands are referred to as Task Nodes, while the remaining nodes with idle computational resources are termed Computation Nodes. It is assumed that within a given time interval, there exist 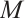 Task Nodes and
Task Nodes and 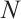 Computation Nodes, and the positions of these nodes do not change within this single interval. The
Computation Nodes, and the positions of these nodes do not change within this single interval. The 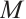 Task Nodes are denoted by the set
Task Nodes are denoted by the set 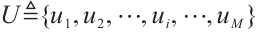 , where
, where 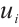 represents the index of a Task Node, and each Task Node has several compute-intensive real-time tasks. The
represents the index of a Task Node, and each Task Node has several compute-intensive real-time tasks. The 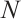 Computation Nodes are denoted by the set
Computation Nodes are denoted by the set 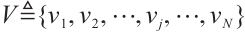 , where
, where 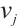 represents the index of a Computation Node. The communication links between the networked computation nodes are represented by the set
represents the index of a Computation Node. The communication links between the networked computation nodes are represented by the set 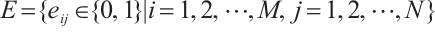 , where
, where 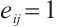 indicates that data transmission is possible between
indicates that data transmission is possible between 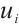 and
and 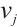 ; conversely,
; conversely, 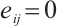 implies that no communication can occur.
implies that no communication can occur.
2.1 Networked Computation Nodes Model
Networked computation nodes can be categorized as Task Nodes and Computation Nodes. The models for these two types of nodes are described below. 1) Task Node. A Task Node 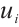 is represented by the 5-tuple
is represented by the 5-tuple 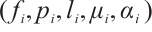 . In this tuple,
. In this tuple, 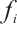 denotes the computational capability of the Task Node, and
denotes the computational capability of the Task Node, and 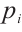 denotes its transmit power.
denotes its transmit power. 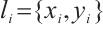 represents the coordinates of the Task Node, where
represents the coordinates of the Task Node, where 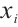 and
and 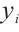 are its horizontal and vertical coordinates in a 2D plane, respectively.
are its horizontal and vertical coordinates in a 2D plane, respectively. 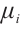 is a proportionality coefficient, representing the baseline level of power consumption for a given computational capability.
is a proportionality coefficient, representing the baseline level of power consumption for a given computational capability. 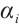 is the computation exponent, which describes the rate at which power consumption increases with computational capability. The energy consumption of the CPU processor can be estimated using the speed-power curve[19]. When the computation speed of the node is
is the computation exponent, which describes the rate at which power consumption increases with computational capability. The energy consumption of the CPU processor can be estimated using the speed-power curve[19]. When the computation speed of the node is 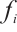 , its speed-power curve is expressed as
, its speed-power curve is expressed as 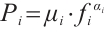 . Each Task Node generates several compute-intensive real-time tasks. It is assumed that
. Each Task Node generates several compute-intensive real-time tasks. It is assumed that 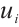 generates
generates 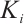 tasks in a time interval. The
tasks in a time interval. The 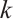 -th task,
-th task, 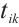 , is represented by a 3-tuple
, is represented by a 3-tuple 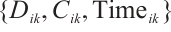 , where
, where 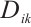 is the data volume of task
is the data volume of task 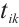 ,
, 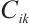 is the required computational workload, and
is the required computational workload, and 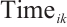 is its completion deadline. 2) Computation Node. A Computation Node
is its completion deadline. 2) Computation Node. A Computation Node 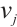 is represented by the 5-tuple
is represented by the 5-tuple 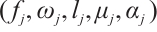 . Here,
. Here, 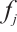 denotes the computational capability of the Computation Node, and
denotes the computational capability of the Computation Node, and 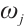 denotes the number of its computation cores.
denotes the number of its computation cores. 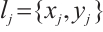 represents its coordinates, where
represents its coordinates, where 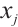 and
and 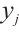 are its horizontal and vertical coordinates, respectively.
are its horizontal and vertical coordinates, respectively. 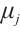 is the scaling factor, representing the baseline power consumption level of computing node
is the scaling factor, representing the baseline power consumption level of computing node 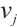 under a given computing power;
under a given computing power; 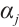 is the computing exponent, describing the rate at which the power consumption of computing node
is the computing exponent, describing the rate at which the power consumption of computing node 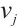 increases with computing power. Together, they determine the power consumption model of the computing node. The speed-power curve of Computation Node
increases with computing power. Together, they determine the power consumption model of the computing node. The speed-power curve of Computation Node 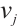 can be expressed as
can be expressed as 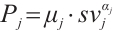 .
.
2.2 Latency Model
The real-time tasks generated by a Task Node can be executed in two ways: local computation or scheduling to another Computation Node. The scheduling decision for task 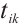 can be represented by
can be represented by 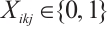 . A value of
. A value of 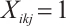 indicates that Task Node
indicates that Task Node 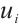 schedules its
schedules its 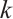 -th task to Computation Node
-th task to Computation Node 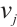 for execution, while
for execution, while 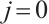 denotes local computation. Each task can only be processed by one Computation Node or locally, which means
denotes local computation. Each task can only be processed by one Computation Node or locally, which means 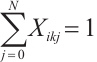 .
.
If scheduling task 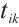 from Task Node
from Task Node 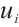 to another Computation Node would not meet the deadline, the Task Node, driven by energy-saving considerations, may choose to execute the task locally. Local execution time of a task
to another Computation Node would not meet the deadline, the Task Node, driven by energy-saving considerations, may choose to execute the task locally. Local execution time of a task 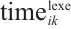 specifically refers to the pure computation time of the k-th task of task node
specifically refers to the pure computation time of the k-th task of task node 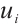 when it is executed locally. In this case,
when it is executed locally. In this case, 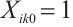 , and its execution time is obtained from equation (1):
, and its execution time is obtained from equation (1):
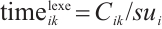 (1)
(1)
When Task Node 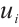 schedules task
schedules task 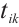 to Computation Node
to Computation Node 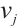 for execution, such that
for execution, such that 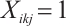 , Orthogonal Frequency Division Multiple Access (OFDMA) is adopted as the data transmission method[20]. The transmission rate
, Orthogonal Frequency Division Multiple Access (OFDMA) is adopted as the data transmission method[20]. The transmission rate 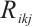 for a Task Node transmitting to a Computation Node can be obtained from equation (2).
for a Task Node transmitting to a Computation Node can be obtained from equation (2).
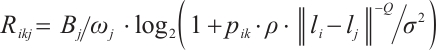 (2)
(2)
In this equation, 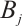 is the network communication bandwidth of
is the network communication bandwidth of 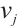 ,
, 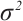 is the Gaussian white noise power,
is the Gaussian white noise power, 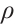 is the channel power gain per unit distance,
is the channel power gain per unit distance, 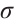 is the path loss exponent, and
is the path loss exponent, and  denotes the Euclidean norm. The transmit power for
denotes the Euclidean norm. The transmit power for 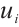 to send
to send 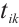 to
to 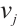 is defined as
is defined as 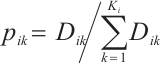 , the denominator
, the denominator 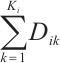 represents the total data volume of all tasks. The total latency
represents the total data volume of all tasks. The total latency 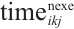 for scheduling task
for scheduling task 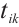 to
to 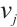 is given by equation (3):
is given by equation (3):
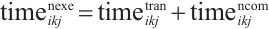 (3)
(3)
In this equation, 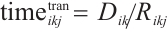 is the transmission time from
is the transmission time from 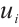 to
to 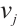 , and
, and 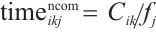 is the computation processing time after the task is transferred. The total execution latency
is the computation processing time after the task is transferred. The total execution latency 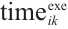 for the k-th task
for the k-th task 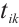 of Task Node
of Task Node 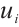 is given by equation (4):
is given by equation (4):
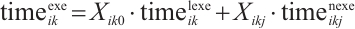 (4)
(4)
System satisfaction, 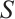 , is defined as the percentage of the total number of tasks successfully executed before their deadlines to the total number of all tasks, which is expressed in equation (5):
, is defined as the percentage of the total number of tasks successfully executed before their deadlines to the total number of all tasks, which is expressed in equation (5):
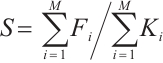 (5)
(5)
In this equation, 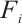 represents the number of tasks from Task Node
represents the number of tasks from Task Node 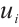 that are successfully completed before their deadlines.
that are successfully completed before their deadlines.
2.3 Energy Consumption Model
Based on the execution method, the energy consumption can be divided into two types: local computation energy and energy consumed for offloaded computation. When a task is computed locally, only local computation energy is incurred. Therefore, the energy consumed by Task Node 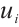 for computing task
for computing task 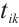 locally is shown in equation (6):
locally is shown in equation (6):
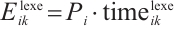 (6)
(6)
The total energy consumption for Task Node 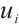 to schedule task
to schedule task 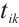 for execution on Computation Node
for execution on Computation Node 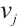 is given by equation (7):
is given by equation (7):
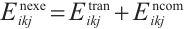 (7)
(7)
In this equation, the transmission energy is 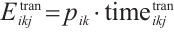 , and the computation energy is
, and the computation energy is 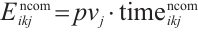 . The total execution energy for the
. The total execution energy for the 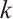 -th task
-th task 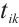 of Task Node
of Task Node 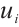 can be obtained from equation (8):
can be obtained from equation (8):
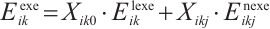 (8)
(8)
2.4 Optimization Problem
This paper comprehensively considers a series of factors, including the heterogeneous communication and computation capabilities of networked computation nodes, the diversified computation requirements and real-time demands of tasks, and the energy consumption of each node. Subject to latency and resource constraints, the objective is to minimize task execution latency and system energy consumption while maximizing overall system satisfaction, thereby achieving an optimal balance between task latency and the energy consumption of Computation Nodes. The optimization problem can be formulated as shown in equation (9):
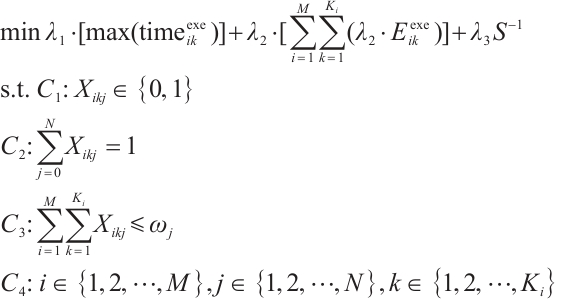 (9)
(9)
In this formulation, 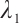 ,
, 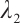 and
and 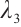 are the weighting factors for latency, energy consumption, and system satisfaction, respectively, satisfying the condition
are the weighting factors for latency, energy consumption, and system satisfaction, respectively, satisfying the condition 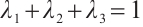 . Constraints
. Constraints and
and  indicate that each task can only be executed either locally or on one Computation Node. Constraint
indicate that each task can only be executed either locally or on one Computation Node. Constraint 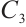 ensures that the number of tasks served by a Computation Node does not exceed its number of idle computation cores.
ensures that the number of tasks served by a Computation Node does not exceed its number of idle computation cores.
3 A Real-Time Task Scheduling Algorithm Based on a Two-Sided Matching Game
Grounded in matching theory[21], this paper proposes a real-time task scheduling algorithm based on a two-sided matching game. This algorithm utilizes a matching game between Task and Computation Nodes to reach a Nash equilibrium. When a stable matching between the two parties is achieved, the total system cost is minimized. A real-time task matching model for Dispersed Computing is considered, which consists of two disjoint finite sets: a set of tasks, denoted as 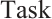 , and a set of Computation Nodes, denoted as
, and a set of Computation Nodes, denoted as 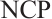 . Each element
. Each element 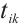 in the
in the 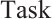 set has a specific preference for each element
set has a specific preference for each element 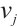 in the
in the 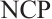 set, denoted by
set, denoted by 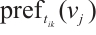 . Similarly, each element
. Similarly, each element 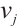 in the
in the 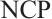 set has a specific preference for each element
set has a specific preference for each element 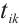 in the
in the 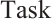 set, denoted by
set, denoted by 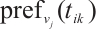 . When task
. When task 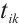 is matched with Computation Node
is matched with Computation Node 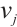 , the decision variable
, the decision variable 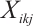 is set to 1.
is set to 1.
3.1 The Preference List
In a matching algorithm, the preference list is a critical component that not only serves as the foundation for the algorithm's execution but also is key to achieving a fair and efficient matching outcome. The rule for calculating the preference value of a task 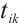 for a Computation Node
for a Computation Node 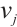 is defined as shown in equation (10):
is defined as shown in equation (10):
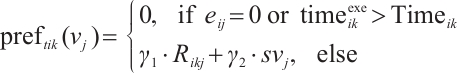 (10)
(10)
In this equation, 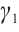 and
and 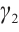 represent the preference weights that a task assigns to the distance and computational capability of a Computation Node, respectively, with the condition
represent the preference weights that a task assigns to the distance and computational capability of a Computation Node, respectively, with the condition 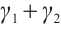 =1. A task
=1. A task 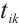 prioritizes Computation Nodes that offer higher transmission speeds and stronger computational capabilities, with the objective of minimizing execution time and reducing the energy consumption of its originating Task Node. The preference value is set to 0 if no communication link exists between the nodes or if the offloading execution time would exceed the task's completion deadline. By calculating the preference value
prioritizes Computation Nodes that offer higher transmission speeds and stronger computational capabilities, with the objective of minimizing execution time and reducing the energy consumption of its originating Task Node. The preference value is set to 0 if no communication link exists between the nodes or if the offloading execution time would exceed the task's completion deadline. By calculating the preference value 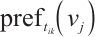 for
for 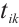 to
to 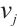 according to equation (10) and sorting these values in descending order, the preference list for all tasks, denoted a s
according to equation (10) and sorting these values in descending order, the preference list for all tasks, denoted a s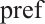 , can be obtained.
, can be obtained.
To address the conflict in preference values between two computing nodes 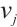 and
and 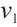 and their transmission rates
and their transmission rates 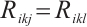 and computing capabilities
and computing capabilities 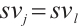 , a secondary judgment rule is added: First, compare the energy consumption efficiency per unit computing power of the two nodes
, a secondary judgment rule is added: First, compare the energy consumption efficiency per unit computing power of the two nodes 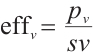 ,
, 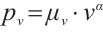 is node power consumption. Select the smaller
is node power consumption. Select the smaller 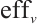 node to reduce system energy consumption; if the energy consumption efficiency is equal, then further compare the number of idle cores
node to reduce system energy consumption; if the energy consumption efficiency is equal, then further compare the number of idle cores 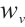 of the nodes, and prioritize the larger
of the nodes, and prioritize the larger 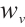 node to avoid delays in subsequent tasks due to resource overload, ensuring that the task's preference selection for computing nodes is more comprehensive and in line with the optimization goals.
node to avoid delays in subsequent tasks due to resource overload, ensuring that the task's preference selection for computing nodes is more comprehensive and in line with the optimization goals.
Defined 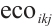 as the energy consumption requirement per unit load on a computing node
as the energy consumption requirement per unit load on a computing node 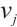 for a task
for a task 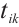 , it quantifies the degree to which task execution consumes the node's energy. The calculation formula is:
, it quantifies the degree to which task execution consumes the node's energy. The calculation formula is:
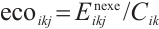 (11)
(11)
The smaller the value of the computational load 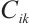 for a task is, the less energy the task can consume to complete the unit computational load, and the less energy pressure it puts on the node. The rule for calculating the preference value of a Computation Node
for a task is, the less energy the task can consume to complete the unit computational load, and the less energy pressure it puts on the node. The rule for calculating the preference value of a Computation Node 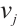 for a task
for a task 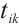 is expressed in equation (12):
is expressed in equation (12):
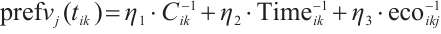 (12)
(12)
In this formula, 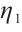 ,
, 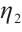 and
and 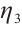 are the preference weights that a Computation Node assigns to the task's computational resource demand, its completion deadline and low energy consumption requirements, respectively, under the condition
are the preference weights that a Computation Node assigns to the task's computational resource demand, its completion deadline and low energy consumption requirements, respectively, under the condition 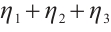 =1. A Computation Node shows a higher preference for tasks that require fewer computational resources and have more urgent real-time requirements. This strategy allows the node to satisfy the task's execution demands while lowering its own energy consumption. By calculating the preference value
=1. A Computation Node shows a higher preference for tasks that require fewer computational resources and have more urgent real-time requirements. This strategy allows the node to satisfy the task's execution demands while lowering its own energy consumption. By calculating the preference value 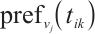 based on equation (12) and sorting these values in descending order, the preference list for the Computation Node,
based on equation (12) and sorting these values in descending order, the preference list for the Computation Node, 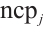 , is generated.
, is generated.
3.2 Two-Sided Matching-Based TaskScheduling Algorithm
After a task has generated its preference list for Computation Nodes, if the list is empty, the task is processed locally. Otherwise, the task submits an execution request to the top-ranked Computation Node in its preference list. The Computation Node, in turn, generates its own preference list for all tasks from which it has received requests. A decision to either accept or reject a task is then made based on this preference list and its own resource availability, thereby achieving a many-to-many stable matching between tasks and Computation Node. The proposed real-time task scheduling algorithm, which is based on a two-sided matching game, takes the sets 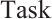 ,
,  , and
, and 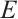 as input, and produces the scheduling decision
as input, and produces the scheduling decision 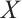 as output. The specific steps are detailed as follows:
as output. The specific steps are detailed as follows:
1) Initialize system parameters. The unmatched task list and the preference list for each Computation Node are initialized as empty. The scheduling decision for all tasks is set to 0. Subsequently, the preference list for every task is generated according to equation (10).
2) Add all tasks from all Task Nodes to the unmatched task list.
3) For each task in the unmatched task list, a preference list of Computation Node is generated according to equation (11). If the preference list for a task is empty, it is scheduled for local execution. Otherwise, the task proposes an execution request to its most preferred Computation Node. Upon receiving the request, Computation Node adds the proposing task to its own preference list. Once all tasks have made their proposals, each Computation Node generates and sorts its preference list in descending order. This signifies that every task has made a locally optimal scheduling decision based on its self-interest. So the unmatched task list is cleared.
4) For each Computation Node 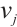 , if the number of received proposals is less than its number of idle cores (
, if the number of received proposals is less than its number of idle cores (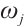 ), it accepts all proposals. Otherwise, it accepts the top
), it accepts all proposals. Otherwise, it accepts the top 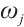 tasks from its sorted preference list. For each accepted task
tasks from its sorted preference list. For each accepted task 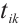 , set its scheduling decision
, set its scheduling decision 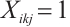 . The remaining proposing tasks are rejected.
. The remaining proposing tasks are rejected.
5) Add all rejected tasks back to the unmatched task list. Repeat Steps 3 and 4 until the unmatched task list is empty. At this point, all tasks have been stably matched, and the algorithm terminates.
4 Experiments and Analysis
4.1 Experiments Setting
The performance of the real-time task scheduling algorithm based on a two-sided matching game was evaluated through simulation experiments. A 1 000 m ×1 000 m two-dimensional planar area was considered, within which multiple networked computation nodes were uniformly distributed. These nodes cooperated to complete a series of compute-intensive real-time tasks. Furthermore, to verify the advantages of Dispersed Computing in comparison with local computation and edge computing, a fixed-position edge server was introduced to simulate the edge computing paradigm within the area. The specific parameters used for the simulation experiments in this section were adopted from Refs. [22-25]. The computing power 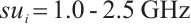 of the task node
of the task node 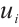 , the computing power
, the computing power 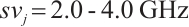 of the compute node
of the compute node 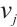 , and the number of idle cores
, and the number of idle cores 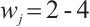 . The task characteristics are as follows:
. The task characteristics are as follows: 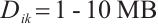 ,
, 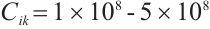 CPU cycles,
CPU cycles, 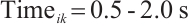 . The algorithm's preference weights were optimized to be
. The algorithm's preference weights were optimized to be 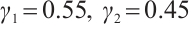 and
and 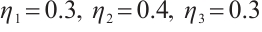 .
.
4.2 Comparison of Results
The real-time task scheduling algorithm based on a two-sided matching game proposed in this paper is denoted as RT-TSMG. To evaluate the effectiveness of RT-TSMG, three common task scheduling algorithms were introduced as benchmarks for comparative analysis. These are:
Random Scheduling (RAN): In this algorithm, a task randomly selects an available Computation Node for execution.
Heterogeneous Earliest Finish Time (HEFT)[26]: This is a policy that, based on task priorities, schedules tasks in a heterogeneous computing environment to minimize the total completion time. In the simulation environment designed here, this algorithm prioritizes tasks that are expected to finish the earliest.
Genetic Algorithm (GA)[27]: This algorithm iteratively evolves a population of candidate solutions through crossover, mutation, and selection operations to produce approximate solutions to the problem. In our experiments, the GA used equation (9) as its fitness function for population iteration.
1) Total task execution cost
The comparison of the total task execution cost between RT-TSMG and the benchmark algorithms under a varying number of users is shown in Fig. 1. It was observed that the total system cost increased with the number of task nodes. This is because a larger number of users lead to more tasks requiring execution, which in turn increases both task execution time and total system energy consumption. By employing an efficient task scheduling rule, RT-TSMG achieved average savings of 8.4%, 3.7%, and 23.2% in total execution cost compared to HEFT, GA, and RAN, respectively. This demonstrates that RT-TSMG significantly improves the system's scalability and efficiency.
 |
Fig.1 Comparison graph of total cost of task execution |
2) Task execution time and energy consumption
The detailed trends of task execution latency and energy consumption with an increasing number of task nodes are depicted in Fig. 2. As shown in Fig. 2(a), the task execution latency for RT-TSMG, HEFT, and GA exhibited an upward trend as the number of task nodes increased. The reason is that the growing number of tasks intensified resource competition, causing some tasks to be allocated to nodes with lower computational capabilities. In contrast, the execution latency of the RAN scheme, which selects nodes randomly, tended towards a stable and balanced state after an initial rise. Furthermore, RT-TSMG fully considers the heterogeneity of task resource demands during its scheduling process. This allows it to rationally prioritize tasks with higher resource requirements to resource-abundant nodes, which significantly reduces the maximum execution latency when all tasks are considered. RT-TSMG achieved average latency savings of 9.5%, 14.3%, and 26.9% compared to HEFT, GA, and RAN, respectively. As shown in Fig. 2(b), the task execution energy consumption also increased with the number of task nodes, and this growth trend became more pronounced in later stages due to intensified resource competition. In this process, the energy consumption of RT-TSMG was slightly higher than that of GA. This is because GA does not consider the balance between task latency and energy consumption, whereas RT-TSMG fully considers balancing the interests of tasks and computation nodes. Consequently, while achieving excellent latency performance, its energy consumption was slightly higher than that of GA. However, it still achieved energy savings of 9.1% and 20.5% compared to HEFT and RAN, respectively.
 |
Fig.2 Comparison graphs of task execution time and energy consumption |
3) System satisfaction
Figure 3(a) shows the trend of system satisfaction with the number of task nodes under different scheduling algorithms, reflecting the proportion of tasks completed before the deadline. As the number of task nodes increases, the system satisfaction of all four algorithms decreases. This is because, with the expansion of task scale, the real-time requirements of some tasks are difficult to meet. Among them, RT-TSMG consistently maintains the best system satisfaction, remaining above 79% when the number of task nodes is no more than 8. Even when the number of task nodes increases to 14, its satisfaction is still significantly higher than HEFT, GA, and RAN. Compared with HEFT, GA, and RAN, RT-TSMG's system satisfaction is improved by an average of 6.7%, 15.2%, and 27.1%, respectively. This result verifies the effectiveness of RT-TSMG in achieving precise alignment between tasks and computing nodes through bilateral matching game theory, demonstrating a significant advantage in ensuring task real-time performance.
 |
Fig.3 Comparison graphs of system satisfaction and system throughput |
4) System throughput
The comparison of system throughput is shown in Fig. 3(b). Throughput is defined as the average number of tasks completed by the system per unit of time. It can be observed from Fig. 3(b) that RT-TSMG significantly outperformed the other schemes in terms of system throughput. This is primarily attributed to RT-TSMG's ability to meticulously consider the time requirements of each task and perform corresponding scheduling optimizations based on task urgency, with the aim of shortening the makespan of all tasks and thereby boosting system throughput. Compared to RAN, HEFT, and GA, RT-TSMG achieved throughput improvements of 67.1%, 23.1%, and 28.8%, respectively. The HEFT scheme may sometimes postpone the scheduling of tasks with longer execution times, while GA, despite optimizing overall system utility, gave slightly less consideration to task latency, resulting in a performance inferior to that of RT-TSMG.
5 Conclusion
To address the unbalanced trade-off between task execution latency and energy consumption in dispersed computing environments, this paper constructed a real-time task scheduling model for such environments. This model is designed to minimize task execution latency and system energy consumption while maximizing overall system satisfaction, under the constraint of ensuring real-time task execution. To obtain a task scheduling strategy, a real-time task scheduling algorithm based on a two-sided matching game was designed. The simulation results demonstrate that the proposed algorithm achieved average savings of 8.4%, 3.7%, and 23.2% in total execution cost compared to the HEFT, GA, and RAN schemes, respectively, and effectively balanced the execution latency of tasks with the energy consumption of Computation Nodes.
Future work will focus on designing a rational incentive mechanism to incentivize privately-owned devices to voluntarily contribute their idle resources. Furthermore, it is imperative to construct secure node interaction mechanisms and reliable communication protocols.
References
- Schurgot M R, Wang M, Conway A E, et al. A dispersed computing architecture for resource-centric computation and communication[J]. IEEE Communications Magazine, 2019, 57(7): 13-19. [Google Scholar]
- Wu H J, Liu F, Liu B, et al. Dispersed computing: Technologies, applications and challenges[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(5): 721-730(Ch). [Google Scholar]
- Sun Y X. Enhancing Anonymity Systems Under Network and User Dynamics[D]. Princeton: Princeton University, 2020. [Google Scholar]
- Michel O, Sonchack J, Keller E, et al. Packet-level analytics in software without compromises[C]//USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 2013). Santa Clara: USENIX Association, 2013: 1-6. [Google Scholar]
- Zaki Y, Pötsch T, Ahmad T. Application-level congestion control: overcoming TCP's limitations in cellular networks[C]//Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 2018). Boston: USENIX Association, 2018: 1-14. [Google Scholar]
- Hui H W. Research on Cybersecurity Model and Algorithm in Dispersed Computing Environment[D]. Beijing: University of Science and Technology Beijing, 2023(Ch). [Google Scholar]
- Ghosh P, Nguyen Q, Krishnamachari B. Container orchestration for dispersed computing[C]//Proceedings of the 5th International Workshop on Container Technologies and Container Clouds. New York: ACM, 2019: 19-24. [Google Scholar]
- Yang H G, Li G, Sun G Y, et al. Dispersed computing for tactical edge in future wars: Vision, architecture, and challenges[J]. Wireless Communications and Mobile Computing, 2021, 2021(1): 8899186. [Google Scholar]
- An X M, Fan R F, Hu H, et al. Joint task offloading and resource allocation for IoT edge computing with sequential task dependency[J]. IEEE Internet of Things Journal, 2022, 9(17): 16546-16561. [Google Scholar]
- Li Y H, Jiang C S. Distributed task offloading strategy to low load base stations in mobile edge computing environment[J]. Computer Communications, 2020, 164: 240-248. [Google Scholar]
- Song S D, Ma S Y, Zhao J M, et al. Cost-efficient multi-service task offloading scheduling for mobile edge computing[J]. Applied Intelligence, 2022, 52(4): 4028-4040. [Google Scholar]
- Kuang Z F, Chen Q L, Li L F, et al. Multi-user edge computing task offloading scheduling and resource allocation based on deep reinforcement learning[J]. Chinese Journal of Computers, 2022, 45(4): 812-824(Ch). [Google Scholar]
- Sacco A, Esposito F, Marchetto G, et al. Sustainable task offloading in UAV networks via multi-agent reinforcement learning[J]. IEEE Transactions on Vehicular Technology, 2021, 70(5): 5003-5015. [Google Scholar]
- Seid A M, Boateng G O, Mareri B, et al. Multi-agent DRL for task offloading and resource allocation in multi-UAV enabled IoT edge network[J]. IEEE Transactions on Network and Service Management, 2021, 18(4): 4531-4547. [Google Scholar]
- Niu Z C, Liu H, Lin X M, et al. Task scheduling with UAV-assisted dispersed computing for disaster scenario[J]. IEEE Systems Journal, 2022, 16(4): 6429-6440. [Google Scholar]
- Poylisher A, Cichocki A, Guo K, et al. Tactical Jupiter: Dynamic scheduling of dispersed computations in tactical MANETs[C]//MILCOM 2021 IEEE Military Communications Conference (MILCOM). New York: IEEE, 2021: 102-107. [Google Scholar]
- Yang C S, Avestimehr A S, Pedarsani R. Communication-aware scheduling of serial tasks for dispersed computing[C]//2018 IEEE International Symposium on Information Theory (ISIT). New York: IEEE, 2018: 1226-1230. [Google Scholar]
- Hu D Y, Krishnamachari B. Throughput optimized scheduler for dispersed computing systems[C]//2019 7th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud). New York: IEEE, 2019: 76-84. [Google Scholar]
- Wang Q, Mei X X, Liu H, et al. Energy-aware non-preemptive task scheduling with deadline constraint in DVFS-enabled heterogeneous clusters[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(12): 4083-4099. [Google Scholar]
- Wang Y Y, Huang J R. Efficient space-time signal processing scheme of frequency synchronization and positioning for sensor networks[J]. Sensors, 2023, 23(4): 2115. [Google Scholar]
- Yang G S, Wang B Y, He X Y, et al. Competition-congestion-aware stable worker-task matching in mobile crowd sensing[J]. IEEE Transactions on Network and Service Management, 2021, 18(3): 3719-3732. [Google Scholar]
- Ma G F, Li H R, Wang X W, et al. Mobility-aware task splitting and computation resource allocation for distributed multi-access edge computing enabled vehicular network[C]//2021 International Conference on Mechanical, Aerospace and Automotive Engineering. New York: ACM, 2021: 164-170. [Google Scholar]
- Wang G Y, Yu X B, Xu F C, et al. Task offloading and resource allocation for UAV-assisted mobile edge computing with imperfect channel estimation over Rician fading channels[J]. EURASIP Journal on Wireless Communications and Networking, 2020, 2020(1): 169. [Google Scholar]
- Guo K, Gao R F, Xia W C, et al. Online learning based computation offloading in MEC systems with communication and computation dynamics[J]. IEEE Transactions on Communications, 2021, 69(2): 1147-1162. [Google Scholar]
- Chen C, Zeng Y N, Li H, et al. A multihop task offloading decision model in MEC-enabled Internet of vehicles[J]. IEEE Internet of Things Journal, 2023, 10(4): 3215-3230. [Google Scholar]
- Topcuoglu H, Hariri S, Wu M Y. Performance-effective and low-complexity task scheduling for heterogeneous computing[J]. IEEE Transactions on Parallel and Distributed Systems, 2002, 13(3): 260-274. [Google Scholar]
- Holland J H. Genetic algorithms[J]. Scientific American, 1992, 267(1): 66-73. [CrossRef] [PubMed] [Google Scholar]
All Figures
|
Fig.1 Comparison graph of total cost of task execution |
| In the text | |
|
Fig.2 Comparison graphs of task execution time and energy consumption |
| In the text | |
|
Fig.3 Comparison graphs of system satisfaction and system throughput |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.